
この章では、Linux カーネルがサポートするファイルシステム内でのファイル管理 の方法や、仮想ファイルシステムの仕組みについて解説する。また、Linux カーネルの 実(real)ファイルシステムがどのようにサポートされているのかについても説明する。
Linux の最も重要な特徴のひとつに、サポートするファイルシステムの豊富さがあ
る。このことが、Linux を非常に柔軟なものにし、他の多くのオペレーティングシス
テムとの共存を可能にしている。書き込みに関して、Linux は 15 のファイルシステム
をサポートしている。それらは、ext, ext2, xia, minix, umsdos, msdos, vfat, proc, smb, ncp, iso9660, sysv, hpfs, affs, それに ufs であり、
おそらく今後もっと多くのファイルシステムが追加されるだろう。
Linux では、Unix の場合と同様に、システム上で使用される個別のファイルシステ ムにアクセスする際、(ドライブ番号やドライブ名といった)デバイス識別子は使われな い。 それらのファイルシステムは、単一の階層的なツリー構造に統合され、それによって ファイルシステムは全体でひとつの実体として表現される。 新しいファイルシステムをマウントする場合、Linux は個々のファイルシステムをこの 単一のツリー構造に付け加える。すべてのファイルシステムは、そのタイプに関わら ず、任意のディレクトリにマウントされ、マウントされたファイルシステムのファイル がそのディレクトリに現存する内容を包み隠す。 そうしたディレクトリは、マウントディレクトリもしくはマウントポイントと呼ばれ る。ファイルシステムがマウントを解除されると、そのマウントディレクトリに存在 したファイルが再度出現する。
ディスクが(たとえば、fdisk を使用して)初期化されるとき、ディスク上
にパーティション構造が設定され、物理ディスクがいくつかの論理パーティションに
分割される。個々のパーティションは、EXT2 ファイルシステムといった単一の
ファイルシステムを保持する。ファイルシステムはファイルを組織し、物理デバイス
のブロック上に保持されたディレクトリやソフトリンク(シンボリックリンク)などによ
る論理的な階層構造を形成する。
ファイルシステムを内包し得るデバイスはブロックデバイスと呼ばれる。
IDE ディスクのパーティション /dev/hda1 は、システム上の最初の IDE
ディスクの最初のパーティションであるが、これはブロックデバイスである。Linux
ファイルシステムは、ブロックデバイスをブロックが単に線形に並んだものと見看して
おり、下位にある物理ディスクのジオメトリに関しては知らないか
もしくは関心を持たない。デバイスの特定ブロックの読み出しリクエストを、その
デバイスにとって意味のある言葉に置き換えること、すなわち、ブロックが保存されて
いるそのハードディスク上の特定のトラック、セクタ、シリンダなどに置き換えるの
は、個々のブロックデバイスドライバの仕事である。ファイルシステムは、それを
保持しているのがどのようなデバイスであっても、同じ方法でそれを見て、認識し、
操作をする。さらに、Linux のファイルシステムを使用すれば、そうした異なる
ファイルシステムが異なるハードウェアコントローラに制御された異なる物理メディア
上にあるということは、(少なくともシステムのユーザにとっては)問題ではなくなる。
ファイルシステムはローカルシステム上にないことすら可能であり、ネットワーク
リンク越しに遠隔操作でマウントされたディスクであってもよい。Linux システムが
SCSI ディスク上にルートファイルシステムを持っている次の例で考えてほしい。
A E boot etc lib opt tmp usr C F cdrom fd proc root var sbin D bin dev home mnt lost+found
ユーザはもちろん、ファイル自体に操作を加えるプログラムでさえ、上記 /C が実はマウントされた VFAT ファイルシステムであり、システムの第一の
IDE ディスク上にあることを知る必要はない。上記の例では(これは実際にわたしが
自宅で使用している Linux システムのものなのだが)、/E は第二の IDE
コントローラ上のマスター IDE ディスクである。プライマリ IDE コントローラが PCI
コントローラで、第二のコントローラが IDE CD-ROM を制御する ISA コントローラで
あるといったことは(ファイルシステム上では)どちらも問題ではない。また、モデムと
そのモデムによる PPP ネットワークプロトコルを使用して、電話で職場のネットワーク
に接続し、この場合、そこにあるわたしの Alpha AXP Linux システム上のファイルシス
テムを /mnt/remote に遠隔操作でマウントすることもできる。
ファイルシステム上のファイルはデータの集合体である。この章の文章(訳注:
原文のこと)が入った元のソースファイルは filesystems.tex というファイル
名の ASCII ファイルである。ファイルシステムは、そのファイルシステム上のファイル
内に含まれるデータを保持するだけでなく、ファイルシステムの構造をも保持してい
る。Linux のユーザやプロセスが、ファイル、ディレクトリ、ソフトリンク(シンボリッ
クリンク)、ファイル保護情報等々として見ている情報はすべて、ファイルシステムに
よって保持されている。
さらに、ファイルシステムはそうした情報を安全、確実に保持しなけれ
ばならない。オペレーティングシステムの基本的な統一性は、ファイルシステムに
依存しているからである。データやファイルの喪失が突発的に起こるオペレーティング
システムを使おうとする人はいないだろう(
脚注1)。
Linux が最初に採用していた minix ファイルシステムは、やや制限が
多く、パフォーマンスにも欠けていた。ファイル名は 14 文字以上になってはなら
ず(これでも、8 文字 + 3文字 というファイル名よりはましである)、最大ファイル
サイズは 64M バイトであった。64 M バイトというと一見充分なサイズのように
思えるが、ちょっとしたデータベースを作ろうとすると大きなファイルサイズは必要
である。Linux 専用にデザインされた最初のファイルシステムである Extended File
System (EXT) は、1992 年 4 月に発表され、多くの問題が改善されたが、それでも
まだパフォーマンスの欠如が感じられた。それゆえ、1993 年、Second Extended File
System (EXT2) が登場した。この章で後ほど詳細に述べるのは、このファイルシステム
についてである。
EXT ファイルシステムが加わった際、重要な発展があった。実(real)ファイル システムがオペレーティングシステムやシステムのサービスから分離され、その インターフェイス層として仮想ファイルシステム(Virtual File System, VFS) が 付加されたことである。VFS によって、Linux は、多くの、しばしば非常に性質の 異なるファイルシステムのサポートが可能になった。そうした個々のファイルシステム は VFS に対し共通のソフトウェアインターフェイスを提供する。Linux のファイル システムの詳細のすべてがソフトウェア上で変換されるので、Linux カーネル の残りの部分やシステム上で実行されているプログラムにとって、あらゆるファイル システムは全く同じに見える。Linux の仮想ファイルシステムによって、同時に多く の異なるファイルシステムを透過的にマウントすることが可能になっている。
Linux の仮想ファイルシステムは、ファイルへのアクセスを出来るだけ速く効率的 なものにするために実装されている。それはファイルやデータの正確な保存をも確実に 行わなければならない。これらふたつの要求は両立し難いものである。ファイルシス テムがマウントされて利用される際、Linux の VFS はそれら個々の情報をメモリに キャッシュする。ファイルやディレクトリに対する作成や書き込み、削除がなされて そのキャッシュ内のデータが変更された場合、ファイルシステムを正しく更新する には細かな配慮が必要になる。実行中のカーネル内にあるファイルシステムのデータ 構造を見ることができるとすれば、ファイルシステムによってデータブロックの読み 書きがなされる様子を観察できるだろう。アクセスされているファイルやディレクトリ を記述するデータ構造体の作成や破棄がなされ、また終始デバイスドライバが動作 していて、データの取り込みや保存を行っている。これらのキャッシュで最も重要な のが、バッファキャッシュ(buffer cache)であり、それは、個別のファイルシステム がその基礎であるブロックデバイスにアクセスする仕組みのなかに組み込まれている。 ブロックがアクセスされると、それはバッファキャッシュに入れられ、それらの 状態に応じて様々なキュー上に保持される。バッファキャッシュは、データバッファを キャッシュするだけではなく、非同期インターフェイスを管理することで、ブロック デバイスドライバの手助けもしている。
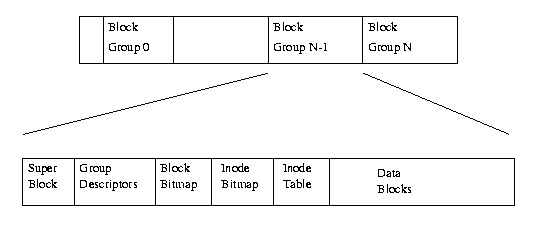
図表(9.1) EXT2 ファイルシステムの物理的レイアウト
EXT2 ファイルシステム(Second Extended File System) は、Remy Card によって
考案された Linux 用の拡張性に富むパワフルなファイルシステムである。
それは Linux コミュニティーにおいてこれまでで最も成功したファイルシステムであ
り、現在出荷されているすべての Linux ディストリビューションの基盤でもある。
[see: fs/ext2/*]
EXT2 ファイルシステムは、多くのファイルシステム同様、ファイルに保持された
データはデータブロックに保存されるという前提のもとに構築されている。これらの
データブロックはすべて同じサイズであり、そのサイズは異なる EXT2 ファイル
システム間で変化することがあるが、特定の EXT2 ファイルシステムにおけるブロック
サイズは(mke2fs コマンドを使用した)ファイルシステム作成時に設定さ
れる。ファイルサイズはすべて、ブロックサイズの整数倍に切り上げられる。ブロック
サイズが 1024 バイトの場合、1025 バイトのファイルは 1024 バイトのブロックふたつ
を占有する。残念なことに、これは平均するとファイルごとに半ブロックのディスク
スペースが浪費されることを意味する。( CPU 対記憶装置という二者択一の原理から
すると)コンピュータでは通常、CPU 効率を犠牲にしてメモリとディスクスペース
を有効利用する。しかしこの場合、Linux は、大部分のオペレーティングシステムと
同様、CPU の負荷を減らすために、比較的効率の悪いディスクの使い方をする。
ファイルシステム上のすべてのブロックがデータを保持しているのではない。ブロック
の一部は、ファイルシステムの構造を記述した情報を保持するために使用されている。
EXT2 はファイルシステムのトポロジーを定義するために、システム上の個々の
ファイルを
inode データ構造体で記述して
いる。
inode が記述する事柄には、ファイル内のデータが保持されたブロックの位置
や、ファイルへのアクセス権、ファイルの変更時間、ファイルタイプなどがある。
EXT2 ファイルシステム上のすべてのファイルは、単一の inode で記述され、
個々の inode は識別のための単一でユニークな番号を持つ。
ファイルシステム上の inode は、inode テーブル内に保存される。
EXT2 のディレクトリとは(それ自体も inode によって記述されている)特殊な
ファイルにすぎず、そのファイルに含まれるのは、そのディレクトリ(が保持する)
エントリの inode へのポインタである。
図表(9.1)は、EXT2 ファイルシステムのレイアウト を示すものであるが、それらは、ブロック構造を持ったデバイス上で連続したブロック を占有している。 個々のファイルシステムからすると、ブロックデバイスとは読み書き可能な一連の ブロックにすぎない。ファイルシステムは物理メディア上のどこにブロックを置くべき かを気にする必要がない。それはデバイスドライバの仕事である。ファイルシステムが ブロックデバイスの持つ情報やデータを読み込む必要があるときは、そのデバイスを サポートするデバイスドライバに対して、ある整数倍の数のブロックを読み込むよう リクエストをする。 EXT2 ファイルシステムは、ディスク上の論理パーティションを、複数のブロック グループ(Block Group)に分割する。個々のブロックグループは、実(real)ファイルや 実ディレクトリの情報やデータをブロックとして保持すると同時に、ファイルシステム の整合性(integrity)を保つために必須の情報を二重化して保持する。二重化が必要なの は、不具合が生じてファイルシステムを復旧しなければならない場合があるからであ る。ブロックグループそれぞれの内容については、サブセクションでさらに詳しく説明 する。
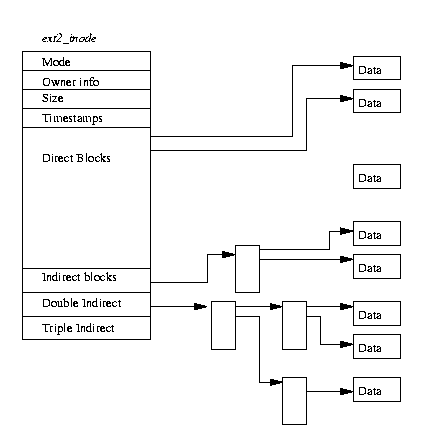
図表(9.2) EXT2 Inode
EXT2 ファイルシステムでは、
inode が
基本的な建築材料(building block)である。
ファイルシステム上のすべてのファイルとディレクトリは、それらと一対一の関係
に立つ inode によって記述される。ブロックグループごとの EXT2
inode は、inode テーブルに保存され、同時に、システムが割り当
てや解放を行った inode の状態を監視するためのビットマップ(bitmap)も
そのテーブルに保存される。
図表(9.2)では、EXT2 inode のフォーマットを示していて、その種々の情報の中には、
次のようなフィールドが含まれている。
[see:
include/linux/ext2_fs_i.h]
このフィールドは 2 種類の情報を保持している。その inode が何を記述しているか ということと、ユーザがそれに対して持つパーミッションである。 EXT2 の場合、inode が記述できるのは、ファイル、ディレクトリ、シンボリック リンク、ブロックデバイス、キャラクタデバイス、FIFO のうちのひとつである。
そのファイルやディレクトリの所有者(owner)に関するユーザ識別子とグループ識別子。 これによって、ファイルシステムは正しいアクセス権限を適切に判断できる。
バイト単位で表されるファイルサイズ
inode が作成された時間とそれが最後に修正
された時間
inode が記述するデータを含んだブロック
に対するポインタ。
最初の 12 個は、その inode が記述するデータを含んだ物理ブロックへのポインタで
あり、最後の 3 つはそれよりも 2 段階間接的なポインタとなっている。たとえば、こ
の二重間接ブロックポインタ(double indirect block pointer)は、物理データブロック
へのポインタ群に対するポインタ群をポイントしている。これは、12 個のデータブロッ
ク以下のサイズしかないファイルは、それより大きいファイルよりも高速にアクセスさ
れることを意味する。
注意すべきなのは、EXT2 inode はスペシャルファイルを表すことができることで
ある。これらは実(real)ファイルではないが、プログラムがそれを使ってデバイスに
アクセスできるようにするためのものである。/dev ディレクトリに
すべてのデバイスファイルが存在することによって、プログラムは Linux 上のデバイス
にアクセスできる。たとえば、mount プログラムは、マウントしようとする
デバイスファイル名を引数に取る。
スーパーブロック(superblock)には、そのファイルシステムの基本的なサイズと
構造(shape)とを記述した情報が含まれる。そこにある情報によって、ファイルシステム
マネージャは、ファイルシステムの使用と管理が可能となる。通常、ファイルシステム
がマウントされる時、ブロックグループ 0 上のスーパーブロックだけが読み込まれるの
だが、個々のブロックグループにはシステムの破壊に備えた複製が含まれている。
様々な情報のなかには次のようなものがある。
[see:
include/linux/ext2_fs_sb.h]
[訳注:ext2_super_block, in
include/linux/ext2_fs.h]
これは、マウント操作を行うソフトウェアが、そのスーパーブロックが本当に EXT2 ファイルシステムのものであるかチェックすることを可能にするためにある。EXT2 の 現行バージョンでは、この番号は 0xEF53 である。
メジャーとマイナーのリビジョンレベルによって、マウント操作を行うコードは、 そのファイルシステムの特定のリビジョンでしか利用できない機能(feature)をサポー トすべきかどうかを判断する。 また、機能互換性フィールド(feature compatibility field)というのが存在し、その 情報は、マウント操作コードが、そのファイルシステム上で新しい機能を安全に使用 することができるかどうかを判断する際の手助けをする。
これらふたつは、ファイルシステムの整合性を完全にチェックすべきかどうかを
システムが判断できるようにするために存在する。マウントカウントは、ファイル
システムがマウントされるたびに加算され、最大マウントカウントに達すると、
「最大マウントカウントに達したので、e2fsck を実行することを薦めます」
という警告メッセージが表示される。
このスーパーブロックのコピーを保持するブロックグループ番号。
バイト数で表されるそのファイルシステムのブロックサイズ。たとえば、1024 バイト等 と表示される。
ひとつのグループのブロック数。これは、ブロックサイズ同様、ファイルシステム作成 時に確定される。
ファイルシステム上のフリーブロックの数。
ファイルシステム上のフリー inode の数。
ファイルシステム上の最初の inode の inode 番号。EXT2 ルートファイルシステム
上での最初の inode は、"/" ディレクトリのディレクトリ
エントリである。
個々のブロックグループは、それを記述するデータ構造体を持っている。スーパー
ブロックと同様に、全ブロックグループに対するグループディスクリプタはすべて、
ファイルシステムの障害に備えて、個々のブロックグループ内で二重化されている。
[see: ext2_group_desc, in
include/linux/ext2_fs.h]
個々のグループディスクリプタには、次のような情報が含まれている。
そのブロックグループに関するブロック割り当てビットマップ(block allocation bitmap)のブロック番号。 これは、ブロックの割り当てと解放の際に使用される。
そのブロックグループに対する inode 割り当てビットマップのブロック番号。 これは、inode の割り当てと解放の際に使用される。
そのブロックグループの対する inode テーブルの開始ブロックのブロック番号。 個々の inode は、下記で述べる EXT2 inode データ構造体によって表されている。
(訳注:これらの項目の説明は原文から省略されています。)
グループディスクリプタは連続的に配置されているので、全体でグループディスク リプタテーブルを形成している。個々のブロックグループには、そのスーパーブロッ クのコピーの後に、グループディスクリプタのテーブル全体が含まれている。 EXT2 ファイルシステムによって実際に使用されるのは、(ブロックグループ 0 にある) 最初のコピーだけである。その他のコピーは、スパーブロックのコピーの場合と同様 に、メインコピーが壊れた場合に備えてのものである。
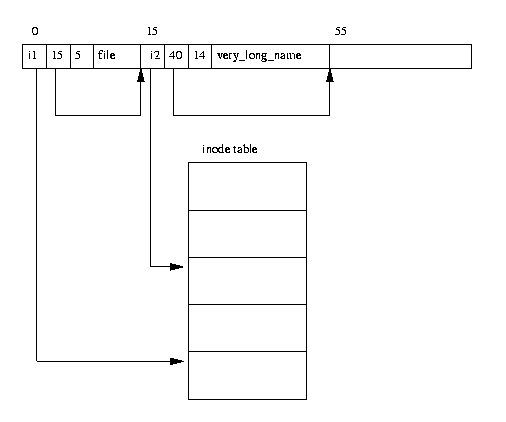
図表(9.3) EXT2 ディレクトリ
EXT2 ファイルシステムにおいて、ディレクトリとは、ファイルシステム上のファイ
ルに対するアクセスパス(access path)の作成と保持のために使用されるスペシャル
ファイルである。図表(9.3)では、メモリ上でのディレクトリエントリのレイアウトが
示されている。ディレクトリファイルは、ディレクトリエントリのリストであり、
個々のエントリには次のような情報が含まれている。
[see: ext2_dir_entry, in
include/linux/ext2_fs.h]
そのディレクトリエントリに対する inode 。これは、ブロックグループの inode
テーブルに保持されている inode 配列へのインデックスになっている。図表(9.3)
では、file という名前のファイルに対するディレクトリエントリが inode
番号 i1 を参照している。
バイト数で示されるそのディレクトリエントリのサイズ
そのディレクトリエントリの名前
すべてのディレクトリにおける最初のふたつのエントリはいつも、標準となって
いる "." と ".." エントリであり、
それらはそれぞれ "現在のディレクトリ" と "親ディレクトリ(parent directory)"
を意味している。
Linux のファイル名は、Unix 上のファイル名と同じフォーマットになっている。
それは、スラッシュ("/")で区切られた一連のディレクトリ名とその最後
にあるファイルの名前から成る。ファイル名の一例は、/home/rusling/.cshrcであり、ここでの /home と /rusling はディレクトリ名で
あり、ファイル名は .cshrc である。他のすべての Unix システムと同様に、
Linux はファイル名そのもののフォーマットには特別な様式を要求しない。それは任意
の長さで、表示可能な任意の文字であってよい。EXT2 ファイルシステム上の
上記ファイルを表す inode を発見するため、システムは、そのファイル自体の
名前に到達するまでファイル名をディレクトリ単位で分解しなければならない。
必要とされる最初の inode は、ファイルシステムのルートディレクトリの inode であるので、ファイルシステム上のスーパーブロック内でその番号を見つける。EXT2 inode を読むためには、適切なブロックグループの inode テーブルでそれを探さなけ ればならない。たとえば、ルートの inode 番号が 42 である場合、ブロックグループ 0 の inode テーブルにある 42 番目の inode を必要とする。ルート inode は EXT2 ディレクトリのものであり、言い換えると、ルート inode のモード(mode)には ディレクトリと記述されているので、そのデータブロックには EXT2 ディレクトリの エントリが含まれている。
home は多くのディレクトリエントリのひとつにすぎず、このディレクトリ
エントリからは、/home ディレクトリが記述する inode の番号が分かる。
rusling のエントリを見つけるにはこのディレクトリを読み込まなければ
ならない。(まず、最初にその inode を読み込んで、次にその inode によって記述
されたデータブロックからディレクトリエントリを読み込む。)そして、その中から
rusling エントリが見つかったら、そこから /home/rusling
ディレクトリを記述する inode の番号が分かる。最後に、/home/rusling
ディレクトリを記述する inode によってポイントされたディレクトリエントリを
読んで、.cshrc ファイルの inode 番号を発見し、その番号によって
そのファイルの情報を含んでいるデータブロックを取得する。
ファイルシステムに共通の問題のひとつに、ファイルの断片化(fragment)傾向が ある。ファイルのデータを保持するブロックはファイルシステム全体に分散して しまい、そのため、データブロック間の距離が遠くなるにつれて、ファイルのデータ ブロックに対する連続したアクセスが困難になりアクセス効率が落ちてしまう。 EXT2 ファイルシステムはこの問題を克服するために、ファイルに新しいデータブロック を割り当てる際、それが現在存在するデータブロックに対し物理的に近接する位置に 割り当てるか、少なくとも元のデータブロックと同じブロックグループ内に割り当て ようとする。そしてそれが出来ない場合のみ、データブロックを別のブロックグループ に割り当てる。
プロセスがデータをファイルに書き込もうとするとき、Linux ファイルシステム は、(データ書き込みの途中で)そのファイルに対して最後に割り当てられたブロック の終端を越えたかどうかをチェックする。 終端を越えた場合、ファイルシステムはそのファイルに新しいデータブロックを割り 当てる処理をする。割り当てが終わるまで、プロセスは実行を中断する。ファイル システムが新しいデータブロックを割り当てて、それに残りのデータを書き込むまで 待ってから、プロセスは実行を再開しなければならない。 EXT2 ブロック割り当てルーチンが最初に実行することは、そのファイルシステムに対 する EXT2 スーパーブロックをロック(lock)することである。割り当てと解放は スーパーブロック内のフィールドの値を変更するので、Linux ファイルシステムは同時 に複数のプロセスがそれをすることを許さない。他のプロセスがさらにデータブロック を割り当てなければならない場合は、実行中のプロセスが終了するまで待つ必要があ る。 スーバーブロックのロック解除を待つプロセスはサスペンド状態になり、スーパー ブロックの制御が現在のユーザによって開放されるまでは実行されない。 スーパーブロックへのアクセスは早い者勝ちの仕組みで許可されるので、プロセスが いったんスーパーブロックの制御を得た場合、処理の終了までその制御を保持する。 スーパーブロックをロックした後、プロセスはファイルシステム上に充分な空き ブロックがあるかどうかをチェックする。 充分な空きブロックがない場合、それ以上割り当てようとしても失敗するので、プロ セスは、そのファイルシステムのスーパーブロックの制御を解放する。
ファイルシステム上に充分な空きブロックがある場合、プロセスはそれを割り当て
ようとする。
[see:ext2_new_block(), in
fs/ext2/balloc.c]
EXT2 ファイルシステムがデータブロックを先割り当て(preallocate)するようビルド
されている場合、それらの中から割り当てを行うことができる。この先割り当てされた
ブロックは実際には存在せず、割り当てられたブロックビットマップ(
block bitmap)内で予約されているだけである。
ファイルに新しいデータブロックを割り当てようとしている場合、そのファイルを
表す VFS
inode には、EXT2 に特有の
prealloc_block と
prealloc_count のふたつのフィールドがあり、
それらはそれぞれ、先割り当てされたデータブロックの最初のブロック番号と、
存在するブロック数を表す。
先割り当てされたブロックが存在しないかブロックの先割り当てが無効な場合、EXT2
ファイルシステムは新しいブロックを割り当てなければならない。まず EXT2 ファイル
システムはファイル内の最後のデータブロックの直後にあるデータブロックが空かどう
かを確認する。理論的には、このブロックは、連続的なアクセスをより高速にできるの
で、割り当てるのに最も効率的なブロックである。このブロックが空でない場合、検索
範囲が広げられ、先ほどの理想的なブロックから 64 ブロック以内にあるブロックを探
す。このブロックは最適ではないにしても、少なくとも非常に近くにあり、そのファイ
ルに属する他のデータブロックと同じブロックグループ内にある。
[see: ext2_new_block(), in
fs/ext2/balloc.c]
そのブロックが空でない場合であっても、プロセスは他のブロックグループを順番
に探して、何らかの空ブロックを見つける。ブロック割り当てコードは、ひとつの
ブロックグループ内のどこかに 8 個の空データブロックのクラスタがあるか調べる。
8 個を一緒に見つけられない場合、それ以下で処理を行う。ブロックの先割り当てが
必要かつ有効とされている場合、当該コードは prealloc_block と prealloc_count を適宜更新する。
空ブロックを見つけた場所に関わりなく、ブロック割り当てコードはブロック グループのブロックビットマップを更新し、バッファキャッシュにデータバッファを 割り当てる。そのデータバッファは、ファイルシステムがサポートするデバイス識別子 と割り当てられたブロックのブロック番号とによってユニークに識別される。 バッファ内のデータは 0 とされ、バッファの内容が物理ディスクに書き込まれていない ことを示すためにそのバッファは「ダーティー(dirty)」とマークされる。最後に、 スーパーブロック自身が、変更されてロックを解除されたことを示すために 「ダーティー」とマークされる。スーパーブロックの空きを待つプロセスがある場合、 キューの最初にあるプロセスが再度実行され、ファイル操作のためにスーパーブロック の排他的な実行制御権を獲得する。プロセスのデータが新しいデータブロックに書き込 まれ、もしそのデータブロックが満杯になると、そのプロセス全体が繰り返されて次の データブロックが割り当てられる。
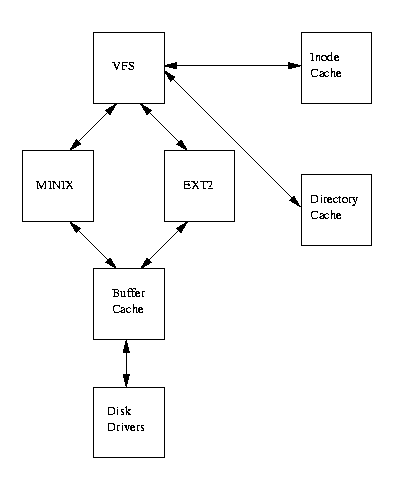
図表(9.4) 仮想ファイルシステムの論理ダイアグラム
図表(9.4)では、Linux の仮想ファイルシステムと実(real)ファイルシステムとの
関係が示されている。仮想ファイルシステムは任意の時間にマウントされた異なる
ファイルシステムすべてを管理しなければならない。そのために、仮想ファイル
システムは、(仮想)ファイルシステム全体、およびマウントされた実(real)ファイル
システムを記述するデータ構造体を管理している。
[see:
fs/*]
やや混乱するかもしれないが、VFS は、EXT2 ファイルシステムがスーパーブロックや
inode を利用する方法と非常に似通った方法で、システムのファイルをスーパーブロッ
クと inode を使って記述している。
EXT2
inode の場合と同様に、VFS
inode も、システム上のファイルやディレクトリを記述している。すなわち、
仮想ファイルシステムの内容やトポロジーを VFS inode を使って記述しているわけで
ある。
ここからは、混乱を避けるために、(仮想ファイルシステムの inode やスーパー
ブロックに関しては) VFS inode や VFS スーパーブロックと書くことで、EXT2 の
inode やスーパーブロックと区別する。
個々のファイルシステムが初期化されると、それは VFS に登録される。これは、
システムのブート時、オペレーティングシステムが初期化される際に行われる。
実(real)ファイルシステムは、カーネルに組み込まれているか、ローダブルモジュール
としてビルドされているかのいずれかである。ファイルシステムモジュールは、システ
ムがそれを必要とするときにロードされるので、たとえば、VFAT ファイルシステムが
カーネルモジュールとして実装されている場合、それは VFAT ファイルシステムがマウ
ントされたときにのみロードされる。ブロックデバイスベースのファイルシステムが
マウントされ、ルートファイルシステムに組み込まれると、VFS はそのファイルシステ
ムが持つスーパーブロックのデータ構造体を読み込まなければならない。
ファイルシステムタイプごとのスーパーブロック読み込みルーチンは、そのファイル
システムのトポロジーを読み解いて、その情報を VFS スーパーブロックのデータ構造体
にマップする。
VFS は、VFS スーパーブロックを保持すると同時に、システム上のマウントされた
ファイルシステムに関するリストを保持しなければならない。
個々の VFS スーパーブロックには、特定の機能を担当するルーチンの情報と、その
ルーチンへのポインタが含まれている。それゆえ、たとえば、マウントされた EXT2
ファイルシステムを表すスーパーブロックには、EXT2 固有の inode 読み込みルーチン
へのポインタが含まれている。
この EXT2 inode 読み込みルーチンは、ファイルシステム固有の inode 読み込みルーチ
ンすべてに共通することでもあるが、VFS inode のフィールドに必要な情報を記入
する。個々の VFS スーパーブロックには、そのファイルシステム上の最初の VFS
inode へのポインタが含まれている。ルートファイルシステムの場合、それは "/" ディレクトリを表す inode である。こうした情報のマッピングは EXT2 ファイ
ルシステムの場合は非常に効率的に行われるが、他のファイルシステムに対してはやや
効率が落ちる。
システム上のプロセスがディレクトリやファイルにアクセスする際、システムの
ルーチンはシステム上の VFS
inode を経由して呼び出さ
れる。
[see:
fs/inode.c]
たとえば、ディレクトリ上で ls とタイプするか、ファイルに対して cat とタイプした場合、仮想ファイルシステムは、そのファイルシステムを表す VFS
inode 群を検索する。
システム上の全ファイルとディレクトリは VFS inode によって表現されているので、
いくつかの inode が繰り返しアクセスされる。それらの inode は inode キャッシュに
保存されて、それらに対するアクセス速度の向上が図られる。inode キャッシュに
inode がない場合、適切な inode を読み込むためにファイルシステム固有のルーチンが
呼び出される。inode を読み込む処理によって、inode は inode キャッシュに入れら
れ、その inode への更なるアクセスによってキャッシュに保存されたままとなる。
ほとんど使用されない VFS inode はキャッシュから削除される。
すべての Linux ファイルシステムは、共通のバッファキャッシュを利用して、基礎
となるデバイスのデータバッファをキャッシュする。これは、ファイルシステムが、そ
のファイルシステムを保持する物理デバイスにアクセスする際、アクセス速度の向上に
役立つ。
[see:
fs/buffer.c]
このバッファキャッシュは、ファイルシステムから独立している。そして、それは、
Linux カーネルがデータバッファの割り当て、読み出し、書き込みのために使用する
メカニズムの中に組み込まれている。これによって Linux のファイルシステムは、
基礎となるメディアやそれをサポートするデバイスドライバから独立できるので、
その仕組みは Linux の明らかな長所となっている。
ブロック構造を持つデバイスはすべて、Linux カーネルに登録され、ブロックベース
の、一般に非同期な、統一的インターフェイスを提供する。SCSI のような比較的複雑な
デバイスでも同様である。実(real)ファイルシステムが基礎となる物理デバイスから
データを読み込む場合、実際にはブロックデバイスドライバにリクエストを送り、ドラ
イバが、その制御するデバイスから物理ブロックを読み込む。このブロックデバイスの
インターフェイスに組み込まれているのが、バッファキャッシュである。
ファイルシステムによってブロックが読み込まれると、それらのブロックは、すべての
ファイルシステムと Linux カーネルによって共有される包括的なバッファに保存され
る。バッファ内の個々のブロックは、ブロック番号とそれを読み込んだデバイス固有の
識別子とによって識別される。したがって、同じデータがしばしば必要とされる場合、
それは、時間のかかるディスクからの読み出しを利用するのではなく、バッファキャッ
シュから取り出される。デバイスの中には先読みをサポートするものがあるが、それは
データブロックが必要とされる場合に備えて、予め予測されるデータブロックを読み込
んでおく機能である。
VFS は、頻繁に使用されるディレクトリをすばやく見つけるために、検索された
ディレクトリのキャッシュをも保持している。
[see :
fs/dcache.c]
実験として、最近表示したことがないディレクトリを表示してみるとそれが分かる。
最初に表示した際、やや時間が掛かるのに気付くが、二度目にその内容が表示される時
は、結果が即座に出る。ディレクトリキャッシュはディレクトリの inode そのものを
保存するのではない。それらは inode キャッシュ内になければならず、ディレクトリ
キャッシュは、完全なディレクトリ名とその inode 番号だけを保存している。
マウントされたすべてのファイルシステムは、VFS スーパーブロックによって
表現される。VFS スーパーブロックは様々な情報を含んでいるが、次にその一部を
示す。
[see:
include/linux/fs.h]
これは、そのファイルシステムが含まれているブロックデバイスのデバイス識別子で
ある。たとえば、システム上の最初の IDE ハードディスクである /dev/hda1
のデバイス識別子は、0x301 である。
inode ポインタ
mounted は、そのファイ
ルシステムの最初の inode をポイントするポインタである。inode ポインタ
covered は、そのファイルシステムがマウントされた
ディレクトリを表す inode をポイントするポインタである。
ルートファイルシステムの VFS スーパーブロックには、covered ポインタ
は含まれない。
バイト単位で表されるそのファイルシステムのブロックサイズ。たとえば、1024 バイ ト。
そのファイルシステムに対する一連のスーパーブロック操作ルーチンへのポインタ。 それらの中には、VFS が inode とスーパーブロックの読み書きに使用するルーチンが ある。
マウントされたファイルシステムの
file_system_type データ構造体へのポインタ。
そのファイルシステムにとって必要な情報へのポインタ
EXT2 ファイルシステムと同様に、VFS 上のすべてのファイルやディレクトリ等は
ユニークな VFS
inode によって表現される。
[see:
include/linux/fs.h]
個々の VFS inode 内の情報は、ファイルシステム固有のルーチンによって、その
基礎となるファイルシステム内の情報から組み立てられる。VFS inode はカーネル
メモリ上にしか存在せず、システムにとって有益である間だけ VFS inode キャッシュ
に保存される。VFS inode に含まれる情報には種種のものがあるが、次にその一部を
示す。
これは、ファイルか当該 VFS inode が指すものを保持しているデバイスのデバイス 識別子である。
これは、その inode の番号であり、それはそのファイルシステム内でユニークな値で ある。デバイスと inode 番号の組み合わせは、その VFS 上において重複することは ない。
EXT2 と同様に、このフィールドが示すの は、その VFS inode が表す対象とそれに対するアクセス権である。
所有者の識別子。
作成、修正、書き込みが起こった時間。
バイト単位で表されるそのファイルのブロックサイズ。たとえば 1024 バイト。
ルーチンのアドレス群へのポインタ。それらのルーチンはファイルシステムに固有で あり、たとえば、その inode が指すファイルを切り縮めるといった、当該 inode に 対する操作を実行する。
現在その VFS inode を使用しているコンポーネントの数。カウント 0 は、その inode が使用されておらず、破棄するか再利用されるべきことを意味する。
このフィールドは VFS inode をロックする際に使用される。たとえば、ファイルシステ ムから読み出されている場合など。
その VFS inode が書き込みをされたかどうかを示す。もしそうである場合、その 基礎となるファイルシステムは適宜修正される必要がある。
ファイルシステム固有の情報。
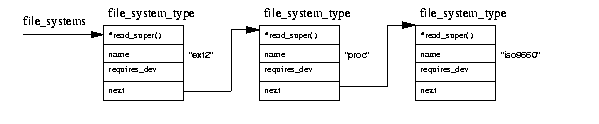
図表(9.5) ファイルシステムの登録
Linux カーネルをビルドするとき、サポートされている個々のファイルシステム
をカーネルに組み込むかどうか質問がなされる。カーネルがビルドされると、ファイル
システム初期化コードには、組み込まれたファイルシステムすべてに関する初期化
ルーチンへの呼び出しコードが含められる。
[see: sys_setup(), in
fs/filesystems.c]
Linux のファイルシステムは、モジュールとしてもビルドすることができる。
その場合、それらは必要に応じてオンデマンドでロードされるか、insmod
コマンドを使用して手動でロードされる。
ファイルシステムモジュールがロードされるときはいつも、それがカーネルに登録
され、ロードが解除されると登録が取り消される。
個々のファイルシステムの初期化ルーチンは仮想ファイルシステムに登録され、
file_system_type データ構造体に
よって表現される。その構造体にはファイルシステムの名前と VFS スーパーブロック
読み込みルーチンへのポインタが含まれている。
図表(9.5)では、file_system_type データ構造
体が、
file_systems リストに登録
され、そのポインタによってポイントされる様子が示されている。個々の file_system_type データ構造体には次のような情報が含まれている。
[see: file_system_type, in
include/linux/fs.h]
このルーチンは、具体的なファイルシステムがマウントされたときに VFS によって 呼び出される。
ファイルシステムの名前。たとえば、ext2 など。
そのファイルシステムは、サポートするデバイスが必要か? すべてのファイルシステム
がそれを保持するデバイスを必要とするわけではない。たとえば、/proc
ファイルシステムはブロックデバイスを必要としない。
どのファイルシステムが登録されているか知るには、/proc/filesystems
を覗けばよい。たとえば、次のように表示されるだろう。
ext2
nodev proc
iso9660
スーパーユーザがファイルシステムをマウントするとき、Linux はまず、システム
コールに渡される引数の妥当性検査をしなければならない。mount コマンド
も基本的なチェックは行うが、現在のカーネルにどのファイルシステムへのサポート
が組み込まれているかや、ユーザによって指定されたマウントポイントが実際に存在
するかといったことは知らないからである。次の mount コマンドについて
考えてほしい。
$ mount -t iso9660 -o ro /dev/cdrom /mnt/cdrom
この mount コマンドはカーネルに 3 つの情報を渡す。ファイルシステム
名、ファイルシステムを含んでいる物理ブロックデバイス、そして 3 つ目に、
現存するファイルシステムのトポロジーにおいて、新しいファイルシステムがどこに
マウントされるべきかということである。
[see: do_mount(), in
fs/super.c]
[see: get_fs_type(), in
fs/super.c]
仮想ファイルシステムが最初にすべきことは、そのファイルシステムを見つける
ことである。そのために既知のファイルシステムのリストを走査するのだが、それは
file_systems によってポイントされ
たリストの中にある
file_system_type データ構造体を個別に探すことによってなされる。
そして、該当する名前が見つかった場合、次にそのファイルシステムが現在のカーネル
でサポートされていること、および現在のカーネルにそのファイルシステムのスーパー
ブロックを読み出すためのファイルシステム固有のルーチンのアドレスが含まれている
ことが分かる。
合致するファイルシステム名を見つけられなかった場合でも、カーネルがオンデマンド
でカーネルモジュールをロードするようビルドされているなら(詳細は
「モジュール」を参照のこと)、処理は継続する。その場合、
カーネルは元の作業を続ける前にカーネルデーモンに対して適切なファイルシステム
をデマンドローディングするようリクエストする。
次に、mount によって渡された物理デバイスがまだマウントされていない
場合、新しいファイルシステムのマウントポイントとなるディレクトリの VFS inode
を見つけなければならない。その VFS inode は、inode キャッシュにあるか、マウント
ポイントがあるファイルシステムをサポートするブロックデバイスから読み出すか
される。inode が分かったら、それがディレクトリかどうか、すでに他のファイル
システムがそこにマウントされていないかどうかを確認するためのチェックがなされ
る。複数のファイルシステムに対するマウントポイントとしては、同一のディレクトリ
は使用できないからである。
この時点で、VFS のマウント処理コードは VFS スーパーブロックを割り当てて、
そのファイルシステムのスーパーブロック読み込みルーチンに対してそのマウント
情報を渡さなければならない。VFS スーパーブロックのすべては
super_block データ構造体の
super_blocks 配列に保存されているので、その
ひとつが、当該マウントのために割り当てられなければならない。スーパーブロック
読み込みルーチンは、それが物理デバイスから読み出しだ情報を基にして VFS
スーパーブロックのフィールドを適切な情報で埋めなければならない。
EXT2 ファイルシステムに関しては、この情報のマッピングもしくは変換は非常に簡単で
ある。しかし、MS-DOS ファイルシステムのようなその他のファイルシステムに関して
は、それほど簡単なタスクではない。ファイルシステムが何であれ、VFS スーパー
ブロックのフィールドを埋めることは、それをサポートするブロックデバイスから、
それが示すすべての情報を読み出さなければならないことを意味する。
ブロックデバイスから読み出しができない場合、もしくはデバイスがそのタイプの
ファイルシステムを含まない場合は、mount コマンドは失敗に終わる。
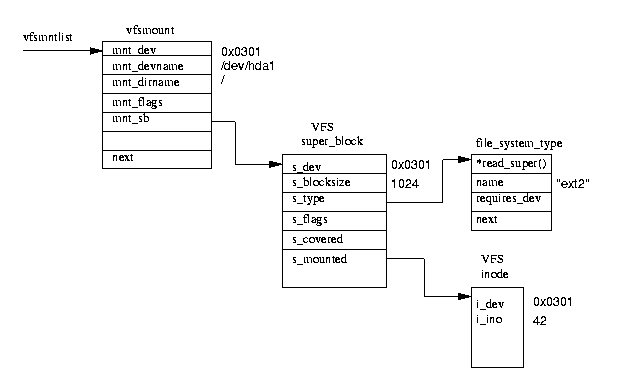
図表(9.6) マウントされたファイルシステム
マウントされた個々のファイルシステムは、
vfsmount データ構造体によって記述される。図表(9.6)を見て欲しい。
それらは
vfsmntlist によってポイントされた
リスト上に待ち行列を作っている。
[see: add_vfsmnt(), in
fs/super.c]
別のポインタである
vfsmnttail は、リストの
最後のエントリをポイントしており、
mru_vfsmnt ポインタは最も最近利用されたファイルシステムをポイントしている。
個々の vfsmount データ構造体には、そのファイルシステムを保持する
ブロックデバイスのデバイス番号、そのファイルシステムがマウントされている
ディレクトリ、そしてそのファイルシステムがマウントされた時に割り付けられた VFS
スーパーブロックへのポインタが含まれている。さらに、VFS スーパーブロックは、
該当する種類のファイルシステムに関する
file_system_type データ構造体とそのファイルシステムのルート inode
をポイントしている。この inode は、そのファイルシステムがロードされている間は、
VFS inode キャッシュのなかに保存される。
仮想ファイルシステム上でファイルの VFS inode を探す ためには、VFS は、名前に含まれる個々のディレクトリを表す VFS inode を問い合わせ ながら、ディレクトリごとにその名前解決をしなければならない。 個々のディレクトリ問い合わせの際には、ファイルシステム固有の問い合わせルーチン が呼び出される。そのルーチンのアドレスはその親ディレクトリを表す VFS inode 内に 保持されている。これが上手くいくのは、個々のファイルシステムのルートディレクト リの VFS inode は、そのシステムの VFS スーパーブロックによってポイントされてい るので、必ず知ることができるからである。 実(real)ファイルシステムによって inode が問い合わせされるたびに、ディレクトリ 用のディレクトリキャッシュがチェックされる。ディレクトリキャッシュにエントリが ない場合、実ファイルシステムは VFS inode を基礎となるファイルシステムからか、 inode キャッシュからのいずれかから取得する。
(訳注: この部分の原文が存在しません。)
わたしの愛車である MG の整備マニュアルにはたいていの場合「組み立ては
分解の逆である」としか説明されていないが、これはファイルシステムの
アンマウントに関する説明にも程度の差はあれ言えることだろう。
[see: do_unmount(), in
fs/super.c]
システム上のファイルシステム内にあるファイルのひとつが何らかのかたちで使用され
ている場合、そのファイルシステムはアンマウントできない。それゆえ
たとえば、プロセスが /mnt/cdrom のディレクトリやその子ディレクトリを
使用している場合、そのディレクトリはアンマウントできない。アンマウントすべき
ファイルシステムが何らかのかたちで使用されている場合、そのファイルシステムの
VFS inode が VFS inode キャッシュにあるかもしれないので、コードはそれをチェック
するために、inode リストを走査し、そのファイルシステムがあるデバイスによって
所有されている inode を探す。マウントされたファイルシステムに関する VFS
スーパーブロックがダーティー(dirty)な場合、それは修正されているということなの
で、修正されたの内容をディスク上のファイルシステムに書き込まれなければならな
い。ディスクへの書き込みが終了したら、VFS スーパーブロックに占有されていた
メモリは、カーネルの空きメモリのプールに戻される。最後に、そのマウントに関する
vfsmount データ構造体は、
vfsmntlist からのリンクを外され、解放される。
[see: remove_vfsmnt(), in
fs/super.c]
マウントされたファイルシステムを操作する際には、そのファイルシステム
の VFS inode が何度も読み出されたり、ある場合には書き込まれたりする。
仮想ファイルシステムは、inode キャッシュを管理して、マウントされたすべての
ファイルシステムへのアクセスを高速化している。
VFS inode が inode キャッシュから読み出されたとき、システムは物理デバイスへの
アクセスを省くことができる。
[see:
fs/inode.c]
VFS inode キャッシュは、ハッシュテーブルとして実装されていて、そのエントリ は、同じハッシュ値を持つ VFS inode のリストへのポインタとなっている。inode の ハッシュ値は、その inode 番号と、ファイルシステムを保持する下位の物理デバイス のデバイス識別子によって計算される。仮想ファイルシステムが inode にアクセスする 必要があるときは、システムはまずそのハッシュ値を計算し、それを inode ハッシュ テーブルへのインデックスとして使用する。それによってシステムは、同じハッシュ値 を持つ inode のリストへのポインタを取得する。そして、個々の inode を順番に 読み出して、探している inode と同一の inode 番号とデバイス識別子の両方を 持つ inode を見つける。
キャッシュに inode が見つかった場合、その inode のカウント値に 1 が足され、
その inode には他にもユーザがいて、ファイルシステムへのアクセスが継続しているこ
とが示される。
見つからない場合、フリーの VFS inode を見つけて、ファイルシステムがメモリから
inode を読み込めるようにしなければならない。
VFS がフリーの inode を取得する方法は、複数ある。
システムがより多くの VFS inode を割り当ててもよい場合は、VFS は新規の inode を
割り当てる。VFS はカーネルページを割り当てて、そのページを新規のフリー inode に
分割し、それらを inode リストに入れる。システム上の VFS inode はすべて、inode
ハッシュテーブルにあると同時に、
first_inode によってポイントされるリストにも存在する。
システムがすでに使用できるすべての inode を使い切っている場合、システムは再利用
されるのにふさわしい inode の候補を探さなければならない。
候補は、0 の利用カウントを付けられた inode である。これは、システムが現在その
inode を使用していないことを示している。たとえば、ファイルシステムのルート
inode のような本当に重要な VFS inode は常に 0 以上の利用カウントを持っている
ので、再利用候補には決してならない。再利用の候補が特定されたら、それは消去
される。VFS inode はダーティー(dirty)になっているかもしれないので、その場合は
ファイルシステムに書き戻される必要があるが、それ以外にもその inode がロックされ
ている場合があり、その際にシステムは処理を継続する前にロックが解除されるのを待
たなければならない。VFS inode の候補は、再利用される前に消去されなければならな
い。
新規の VFS inode を見つけ出す方法に関わらず、ファイルシステム固有のルーチン が呼び出されて、基礎となる実ファイルシステムから読み出された情報でその inode の フィールドを埋める必要がある。その情報が書き込まれている間、新しい VFS inode は、利用カウント 1 を設定され、有効な情報を所持するようになるまでどこからもアク セスされないようにロックされる。
実際に必要な VFS inode を見つけだすために、ファイルシステムは他のいくつかの inode にアクセスしなければならない場合がある。これが起こるのはディレクトリの 読み込みのときである。最後のディレクトリの inode だけが必要なのだが、その途中 にあるディレクトリの inode も読み込まなければならない。VFS inode キャッシュが 使用され、それが満杯になると、ほとんど使われない inode は破棄され、より利用頻度 の高い inode がキャッシュに残る。
よく利用されるディレクトリへのアクセスを高速化するために、VFS はディレクトリ
エントリのキャッシュを管理している。
[see:
fs/dcache.c]
実ファイルシステムからディレクトリの
問い合わせがあると、それらの詳細がディレクトリキャッシュに入れられる。
たとえばディレクトリを表示させたり、その中のファイルをオープンするといった
同じディレクトリへの問い合わせが続く場合、そのディレクトリはディレクトリ
キャッシュで発見できる。短い(15 文字までの)ディレクトリエントリのみがキャッシュ
されるのだが、短いディレクトリ名が最も頻繁に使われるため、この方法は合理的であ
る。たとえば、/usr/X11R6/bin は、X サーバの実行中に、非常に頻繁にアク
セスされる。
ディレクトリキャッシュはハッシュテーブルから成り、その個々のエントリは、 同じハッシュ値を持つディレクトリキャッシュエントリのリストをポイントしている。 ハッシュ関数は、そのファイルシステムを保持するデバイスのデバイス番号と ディレクトリ名とを利用して、そのハッシュテーブルへのオフセットとインデックス とを計算する。それによって、キャッシュされたディレクトリは高速に発見される ことが可能になる。キャッシュ内でのエントリ検索の問い合わせに時間がかかりすぎ たり、エントリを見つけられないようなキャッシュでは意味がない。
キャッシュを有効かつ最新に保つために、VFS は最長時間未使用( Least Recently Used, LRU)のディレクトリキャッシュエントリのリストを保持している。ディレクト リが問い合わせを受けて、そのディレクトリのエントリが初めてキャッシュに入れら れるとき、それは第一レベルの LRU リストの末尾に付け加えられる。キャッシュが 満杯の場合は、その LRU リストの先頭に存在するエントリを削除することで付け加え られる。 ディレクトリエントリが再度アクセスされると、それは第二レベルの LRU キャッシュ の末尾に入れられる。これが満杯の場合も同様に、第二レベルの LRU キャッシュリスト の先頭にあるディレクトリエントリと入れ替わる形となる。第一レベルと第二レベルの LRU リストの先頭にあるエントリを立ち退かせるという方法は妥当である。リストの 先頭にエントリがあることの唯一の理由は、それらが最近アクセスされていないという ことだからである。アクセスがあれば、リストの後尾近くに移る。第二レベルの LRU キャッシュリストにあるエントリは、第一レベルの LRU キャッシュリストにあるエント リよりも安全である。なぜなら、第二レベルにあるエントリは、問い合わせを受けた だけでなく、繰り返し参照されているからである。
REVIEW NOTE: Do we need a diagram for this?
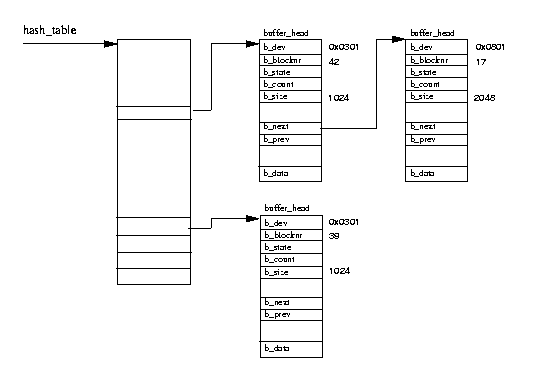
図表(9.7) バッファキャッシュ
マウントされたファイルシステムが利用される場合、ファイルシステムはデータ
ブロックを読み書きするためにブロックデバイスに対する多くのリクエストを行う。
データブロックの読み書きするためのリクエストはすべて、標準のカーネルルーチン
の呼び出しを経由して、
buffer_head データ
構造体で定義されたデバイスドライバに渡される。
この構造体はブロックデバイスドライバに必要なすべての情報を提供する。
デバイス識別子は固有のデバイスを識別し、ブロック番号はドライバにどのブロックを
読み出すべきかを示す。すべてのブロックデバイスは、同一サイズのブロックの
線形的な集合であると見看される。物理ブロックデバイスへのアクセスをスピード
アップするために、Linux はブロックバッファのキャッシュを管理する。
システム上の
すべてのブロックバッファは、使用されていない新しいバッファでさえ、このバッファ
キャッシュのどこかに保存される。このキャッシュはすべての物理ブロックデバイス
間で共有される。どのような時にもそのキャッシュには多くのブロックバッファが
ある。それらはシステムのブロックデバイスのひとつに属していて、しばしば種々の
異なる状態(
state)にある。
有効なデータがバッファキャッシュから入手可能な場合、
それによってシステムが物理デバイスにアクセスする手間が省かれる。ブロック
デバイスに対する読み込みや書き出しで使用されたブロックバッファはすべて、
バッファキャッシュに入れられる。時間の経過によって、それらは、より必要性の高い
バッファと交代するためにキャッシュから削除されるか、頻繁にアクセスされるため
キャッシュに残るかする。
キャッシュ内のブロックバッファは、それを保持するデバイスの識別子とバッファ のブロック番号とによってユニークに識別される。バッファキャッシュはふたつの 機能別部分から構成される。最初の部分は、空のブロックバッファのリストである。 サポートされるバッファサイズごとにひとつのリストがあり、システム上の空のブロッ クバッファは、初めて作成されたり、削除されたときに、それらのリスト上の待ち行列 に置かれる。現在サポートされているバッファサイズは、512, 1024, 2048, 4096, そして 8192 バイトである。第二の部分は、キャッシュそのものである。これは ハッシュテーブルであり、そのハッシュテーブルは同じハッシュインデックスを持つ バッファに対するポインタの配列である。ハッシュのインデックスは、該当 ブロックを保持するデバイスの識別子とデータブロックのブロック番号から生成され る。 図表(9.7)では、ハッシュテーブルがいくつかの エントリとともに示されている。 ブロックバッファはフリーリストのいずれかひとつにあるか、バッファキャッシュの 中に存在する。バッファキャッシュにあるときは、それらは最長時間未使用(LRU) リスト上のキューにも置かれる。LRU リストは個々のタイプのバッファごとに存在し、 システムがそのタイプのバッファ上で処理をする際、たとえば、バッファ内の新しい データをディスクに書き出す際などに使用される。バッファタイプとはその状態 (state)を反映するものであり、Linux では現在次のようなタイプがサポートされて いる。
未使用で新しいバッファ
ロックされ、書き込まれるのを待つバッファ。
ダーティバッファ。それには新しい有効なデータが含まれ、書き込みがされる予定 だが、今のところ書き込みのスケジュールが回って来ていないもの。
共有バッファ。
以前は共有であったが、現在は共有されていないバッファ。
ファイルシステムは、基礎となる物理デバイスからバッファを読み出す必要が あるときには、バッファキャッシュからブロックを取得しようとする。 バッファキャッシュから取得できない場合、適切なサイズのフリーリストから 未使用バッファを取得し、その新しいバッファがバッファキャッシュに入る。 ファイルシステムが必要とするバッファがバッファキャッシュにある場合、バッファは 更新(update)されている場合とされていない場合がある。更新されていないか、それが 未使用ブロックバッファである場合は、ファイルシステムは、デバイスドライバによっ て適切なデータブロックがディスクから読み出されるようリクエストする。
すべてのキャッシュと同様に、バッファキャッシュは、効率よく実行され、バッファ
キャッシュを利用するブロックデバイス間で公平にキャッシュエントリが割り当てられ
るように管理されなければならない。Linux は bdflush カーネルデーモン
を使用して、キャッシュに関する多くの細かな作業を実行しているが、それらのいく
つかは、キャッシュが使用された結果として自動的に実行される。
bdflush カーネルデーモンは、システムがダーティ(dirty, 更新待ち)
バッファを多く持ちすぎている場合に、システムに対して動的に反応するシンプルな
カーネルデーモンである。
[see: bdflush(), in
fs/buffer.c]
データを保持するバッファは、時々ディスクへと書き戻さなければならない。
そのデーモンは、起動時にはシステム上のカーネルスレッドとして起動される。少し
ややこしいのだが、それは "kflush" と呼ばれ、その名前は、システム上の
プロセスを表示する ps コマンドを使うと見ることができる。
たいていこのデーモンはスリープ状態で、システム上のダーティバッファの数が多く
なりすぎるのを待っている。バッファが割り当てられたり破棄されたりすると、システ
ム上のダーティバッファの数がチェックされる。システム上のバッファの総数のパーセ
ンテージとしてダーティバッファが多くなりすぎると、bdflush は目を覚ま
す。デフォルトの境界線は 60% だが、システムがバッファの不足で困っている場合は、
bdflush は強制的に目覚めされられる。この値は、update コマンド
を使って確認や変更が可能である。
# update -d bdflush version 1.4 0: 60 Max fraction of LRU list to examine for dirty blocks 1: 500 Max number of dirty blocks to write each time bdflush activated 2: 64 Num of clean buffers to be loaded onto free list by refill_freelist 3: 256 Dirty block threshold for activating bdflush in refill_freelist 4: 15 Percentage of cache to scan for free clusters 5: 3000 Time for data buffers to age before flushing 6: 500 Time for non-data (dir, bitmap, etc) buffers to age before flushing 7: 1884 Time buffer cache load average constant 8: 2 LAV ratio (used to determine threshold for buffer fratricide).
データを書き込まれて更新待ち状態になり、bdflush が合理的な数の
ダーティバッファをディスクに書き戻そうとする場合はいつも、ダーティバッファの
すべてが、
BUF_DIRTY LRU リストにリンク
される。この数も確認可能であり、update コマンドによって制御できる。
デフォルト値は 500 である。(上記を参照)
update コマンドは単なるコマンドではなく、デーモンでもある。
(システム初期化の際に)スーパーユーザ権限で起動されると、それは定期的に
古くなったダーティバッファのすべてをディスクに書き戻す(フラッシュする)。
これが実行される際には、bdflush と似通ったシステムサービスルーチン
が呼び出される。
[see: sys_bdflush(), in
fs/buffer.c]
ダーティバッファは(システムサービスルーチン)終了時に、元のディスクに書き戻す
ため、システム時間が(バッファの構造体に)付け加えられる。update コマン
ドが実行されるときは、いつも、システム上のダーティバッファすべてを検査し、
フラッシュすべき時刻を過ぎているものを探す。フラッシュすべき時刻をすぎた
すべてのバッファは、ディスクに書き戻される。
/proc ファイルシステムは、Linux の仮想ファイルシステムの能力を
如実に示すものである。そのファイルシステムは実在しない。(これも、Linux の魔術
のひとつである。) /proc ディレクトリも、そのサブディレクトリも、
その中のファイルも実在しない。では、どうして cat /proc/devices という
コマンドを実行できるのか? /proc ファイルシステムは、実ファイル
システムと同様に、仮想ファイルシステムに登録されている。しかし、VFS が
/proc ファイルシステムを呼び出して、そのファイルやディレクトリを
オープンするために inode をリクエストしたときに、 /proc ファイル
システムは、カーネル内の情報からそのファイルやディレクトリを(動的に)作成する。
たとえば、カーネルの /proc/devices ファイルはそのデバイスを記述する
カーネルのデータ構造体から生成されている。
/proc ファイルシステムは、カーネル内部の実行状態への窓を、ユーザ
が読みとれるような形で提供する。Linux カーネルモジュール(
「モジュール」の章を参考)のような Linux サブシステムの
いくつかは、/proc ファイルシステム内にエントリを作成している。
Linux は、Unix のあらゆるバージョンと同様に、ハードウェアデバイスをスペ
シャルファイルで表現している。たとえば、/dev/null はヌル(null)デバイス
である。デバイスファイルはシステム上のデータ空間を使用しない。それは、単なる
デバイスドライバへのアクセスポイントである。EXT2 ファイルシステムと Linux VFS
はどちらもデバイスドライバを特別なタイプの inode として実装している。デバイス
ファイルには、キャラクタスペシャルファイルとブロックスペシャルファイルの
二種類がある。
カーネル自体の内部で、デバイスドライバによるそうしたファイルのオープンや
クローズといった、ファイル操作の意味が定義されている。
キャラクタデバイスでは、キャラクタモードでの I/O 操作が可能であり、ブロック
デバイスではすべての I/O 操作がバッファ経由で行われるよう要求される。
デバイスファイルに対する I/O リクエストがなされると、そのリクエストはシステム
上の適切なデバイスドライバに送られる。これはしばしば実際のドライバでなく、
SCSI デバイスドライバ層といったあるサブシステムの疑似デバイス(pseudo-device)
ドライバである場合がある。デバイスファイルは、デバイスタイプを識別するメジャー
番号と、同じメジャー番号の中での実際のユニット(unit)もしくはインスタンス
(instance)を識別するマイナー番号とで参照される。
たとえば、システム上の最初の IDE ディスクコントローラ上にある IDE ディスクは、
メジャー番号 3 であり、IDE ディスクの最初のパーティションはマイナー番号 1 と
なる。したがって、/dev/hda1 の ls -l の結果は次のようになる。
[see: Linux の全メジャー番号については、
include/linux/major.h]
$ ls -l /dev/hda1 brw-rw---- 1 root disk 3, 1 Nov 24 15:09 /dev/hda1
カーネル内部では、すべてのデバイスが
kdev_t データタイプによってユニークに記述される。このデータは 2 バイト長であり、
最初のバイトにはデバイスのマイナー番号が含まれ、二番目のバイトにはメジャー番号
が保持されている。
[see:
include/linux/kdev_t.h]
上記の IDE デバイスは、カーネル内の 0x0301 に保持されている。ブロックデバイス
やキャラクタデバイスを表す EXT2
inode
は、デバイスのメジャー番号とマイナー番号を、ブロックを直接ポイントする(配列の)
先頭のポインタに保持している。
それが VFS によって読み出されるとき、それを表す VFS
inode データ構造体は、
i_rdev
フィールドに正しいデバイス識別子を設定する。
(脚注 1): Linux には、大勢の開発者がいる。いくつかのオペレーティングシステムに は、もっと大勢の弁護士がいるらしい。