
プロセスは、他のプロセスやカーネルと相互に通信することで、自らの作業の調整 を図っている。Linux では、いくつかのプロセス間通信(Inter-Process Communication, IPC)のメカニズムがサポートされている。シグナルとパイプは その典型であるが、Linux は System V IPC メカニズムもサポートしている。System V IPC という名称は、Unix の当該リリースで初めて登場したことからその名が付けられ ている。
シグナルは、Unix システムで使用される最も古いプロセス間通信の方法である。 シグナルは、ひとつ以上のプロセスに対して非同期イベント(asynchronous events)を 伝達するために使用される。シグナルが生成されるのは、キーボード割り込みがあっ たり、プロセスが仮想メモリ内に存在しない場所にアクセスしようとしてエラーが起 きたときなどである。シグナルは、シェルが子プロセスに対してジョブ制御の信号を 伝達するときにも利用される。
一連の定義済みシグナルがあり、それらはカーネルによって生成されるが、正しい
権限を与えられているなら、システム上のカーネル以外のプロセスでも生成が可能で
ある。kill コマンド (kill -l) を使用すれば、システム上で
利用可能なシグナルのリストを得ることができる。わたしの Intel の Linux ボック
スでは次のような結果が表示された。
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP 6) SIGIOT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP 21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ 26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
シグナルの番号は、Alpha AXP の Linux ボックスでは異なったものになる。プロセ スは、生成されたシグナルの大部分を無視することもできるが、ふたつだけ有名な 例外がある。プロセスの実行を停止させる SIGSTOP シグナルと、プロセスを終了させ る SIGKILL シグナルであり、これらは無視できない。それ以外については、プロセス が様々なシグナルをどう処理するかを自分で選択できる。プロセスはシグナルを ブロックすることができるが、ブロックしない場合は、自分自身で処理するか、 あるいはカーネルに処理してもらうこともできる。 カーネルがシグナルを処理する場合、そのシグナル が要求するデフォルトの行為が実行される。たとえば、プロセスが SIGFPE (floatin point exception)シグナルを受け取った際のデフォルトの行為は、core dump を行って 終了することである。シグナルには、内在的な相対的優先順位といったものはない。 ひとつのプロセスに対してふたつのシグナルが同時に生成された場合、それらがプロ セスに渡される順番も、プロセスが処理すべき順番も決まっていない。また、同じ 種類の重複したシグナルを処理するメカニズムというのも存在しない。プロセスは、 SIGCOUNT をひとつだけ受け取ったのか、それともそれを 42 個受け取ったのかと いうことを伝えるべき方法を持たない。
Linux のシグナルの実装では、プロセスの
task_struct 構造体に保存された情報が利用される。
サポートされるシグナルの数は、プロセッサのワード(
word)サイズに制限されている。
32 ビットのワードサイズを持つプロセッサは、32 個のシグナルを持つことが出来る
が、Alpha AXP のような 64 ビットプロセッサでは 64 個までである。
まだ処理の済んでいないシグナルは、task_struct の
signal フィールドに保存され、
blockd フィールドにブロックされたシグナルの
シグナルマスク(
signal mask)が保持される。
SIGSTOP と SIGKILL を除いて、すべてのシグナルはブロックすることができる。
ブロックされたシグナルが生成されると、それはブロックを解除されるまで未処理
状態に留まる。また、Linux は、個々のプロセスが受け取るかもしれないあらゆる
シグナルをどう処理するのかに関する情報を保持しているのだが、その情報は
sigaction データ構造体の配列に保存され、個々
のプロセスの task_struct データ構造体によってポイントされている。
それ以外にも、task_struct には、シグナルを処理するルーチンのアドレスか、もしくはフラグのいずれか
が含まれている。フラグを使う場合、プロセスは、当該シグナルを無視するか、
そのシグナルの処理をカーネルに代行させるかをそのフラグによって Linux に伝える。
プロセスは、システムコールを使ってシグナルに対するデフォルト処理を変更すること
ができ、そのシステムコールによって適切なシグナルに関する sigaction
構造体を変更したり、blockd マスクを変化させたりする。
システム上の全プロセスが他のどのプロセスにもシグナルを送れるというわけでは
ないが、カーネルとスーパーユーザにはそれが可能である。通常のプロセスは、
同じ uid や gid を持つプロセスか、同じプロセスグループに
属するプロセスにのみシグナルを送れる。
(脚注1)
シグナルの生成は、
task_struct の signal フィールドにある適切なビットを
セットすることにより為される。プロセスがシグナルをブロック
しておらず、待機中だが割り込み可能な(INTERRUPTIBLE な)状態にある場合、そのプロ
セスは、目を覚まして実行中(RUNNING)状態に置かれ、実行キューへ登録されて、その
登録を確認される。それによって、スケジューラは、システムの次のスケジュールに
おいて、そのプロセスを実行の候補者と見なす。デフォルトの処理が必要な場合、
Linux はそのシグナルの処理を最適化できる。たとえば、シグナル SIGWINCH
(X Window のフォーカス変更)が生成され、それに対してデフォルトのハンドラが使用
される場合は、そのハンドラによって適切な処理がなされるので、それ以外の特別な
処理はなされない。
シグナルは生成されてすぐにプロセスに渡されるわけではない。それらはプロセスが
再び実行されるまで待たなければならない。プロセスがシステムコールによって終了
するときはいつでも、
signal と
blocked フィールドがチェック
され、もしプロセスが予めブロックしていないシグナルが存在する場合は、その時点で
ようやくプロセスにシグナルを渡すことができる。これは非常に信頼性の低い方法に
思われるかもしれないが、システム内のすべてのプロセスは、始終システムコールを
発して、たとえば、端末に文字を書き込んだりしているので、こうした仕組みはやむを
得ないものである。しかし、プロセスは、自分が望む場合は、自らシグナル待ちの
状態になることもできる。その場合、シグナルが送られるまで、割り込み可能な
サスペンド状態となる。その際、Linux のシグナル処理のコードは、現在ブロック
されていないシグナルを受け取るたびに、
sigaction 構造体を調べる。
プロセスのシグナルハンドラがデフォルトにセットされている場合、カーネルが
そのシグナルを処理する。SIGSTOP シグナルのデフォルトのハンドラは、現在のプロ
セスの状態を停止状態(STOPPED)とし、スケジューラを起動して新しいプロセスを実行
する。SIGFPE シグナルのデフォルトの処理は、そのプロセスに core dump させ、
それを終了させる。反対に、プロセスが自分自身のシグナルハンドラを指定すること
もできる。これは、そのシグナルが生成されると必ず呼び出されるルーチンとな
り、
sigaction 構造体がそのルーチンのアド
レスを保持する。その場合、カーネルはプロセスのシグナル処理ルーチンを呼び出
さなければならず、その呼び出し方法はプロセッサに固有のものであるが、
すべての CPU が対処しなければならない事実として、カーネルモードで実行されて
いるカレントプロセスは、カーネルやシステムルーチンを呼び出した時のユーザモー
ドのプロセスへと戻ろうとしているということである。
この問題を解決するために、プロセスのスタックとレジスタが操作される。プロセスの
プログラムカウンタには、そのシグナル処理ルーチンのアドレスが設定され、
そのルーチンへのパラメータがコールフレームに付加されるか、レジスタに渡される。
プロセスが再び実行を開始するとき、シグナル処理ルーチンは通常通り呼び出された
かのように見える。
Linux は POSIX に準拠しているので、プロセスは、特定のシグナル処理ルーチン が呼び出されたとき、そのシグナルをブロックするかどうか指定ができる。 これは、プロセスのシグナル処理ルーチンの呼び出しがなされている間にブロック マスクを変更することを意味する。シグナル処理ルーチンが終了したら、そのブロック マスクの値は元に戻されなければならない。したがって、Linux は、片づけ用のルー チン(tidy up routine)へのコールを追加して、そのルーチンがシグナルを受け取った プロセスのコールスタック上のブロックマスクを元に戻す。 また、Linux は、複数のシグナル処理ルーチンの呼び出しが必要な場合、それらを スタックに積んでおいて、ひとつの処理ルーチンが終了したら次のルーチンを呼び出す 操作を繰り返して、最後に片づけルーチンを呼び出すという方法でそうした処理を最適 化している。
一般的な Linux シェルは、すべてリダイレクション(redirection)をサポートして いる。たとえば、次のようなリダイレクションがある。
$ ls | pr | lpr
上記の例では、ディレクトリ内のファイルを表示する ls コマンドの
出力をパイプ処理して、pr コマンドの標準入力に振り向けて、pr
にページ処理をさせる。そうして、そのコマンド出力をパイプ処理して、lpr
コマンドの標準入力に振り向けて、デフォルトプリンタ上でその結果をプリントさせ
ている。すなわち、パイプとは、あるプロセスの標準出力を別のプロセスの標準入力
へと繋ぐ、片方向性をもったバイトストリームである。その場合、どちらのプロセス
もリダイレクションを意識せず、通常通りに振る舞う。プロセス間にそれらの一時的
なパイプを設定するのはシェルの役目である。
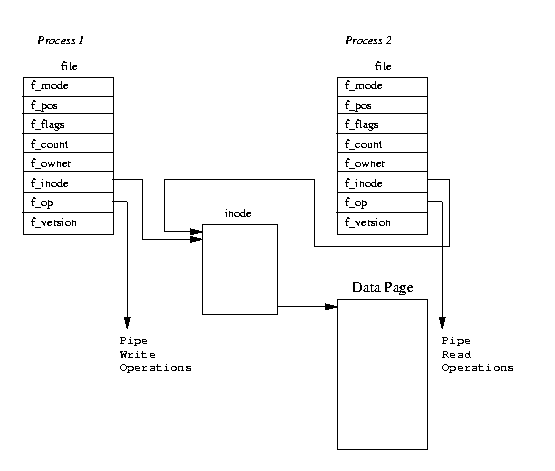
図表(5.1) パイプ
Linux において、パイプの実装には、ふたつの
file データ構造体が使用される。メモリ内のある物理ページをポイントする VFS
inode を一時的に作成して、それをふたつの構造体で同時にポイントするのである。
図表(5.1)では、それぞれの file データ構造体が、ファイル操作ルーチン
の配列の異なる要素をポイントしている様子が示されている。ひとつは、パイプへ
の書き込みであり、もうひとつは、パイプからの読み出しである。
[see: include/linux/inode_fs_i.h](ママ)
(訳注:
pipe_fs_i.h ?)
この方法では、通常ファイルへの書き込み処理と読み出し処理をする汎用システム
コール間にある基礎的な違いは隠蔽される。書き込みプロセスがパイプに書き込むと
き、バイト列は共有データページにコピーされ、読み出しプロセスがパイプから読み
出すときは、バイト列がその共有データページからコピーされる。Linux は、その
パイプへのアクセスを同期させなければならない。Linux は、パイプからの読み出し
と、そこへの書き込みとが確実に歩調を合わせるようにしなければならず、そのため
に Linux は、ロック(
lock)や待ち行列(
wait queue)やシグナル(signal)といった仕組
みを利用している。
書き込みプロセスがパイプに書き込もうとするときは、標準の書き込みライブラリ
関数を使用する。
それらの間でやり取りされるファイルディスクリプタはすべて、書き込みプロセ
スが持つ一連の
file データ構造体へのインデッ
クスとなっていて、それら個々の構造体がオープンされたファイル、この場合には
オープンされたパイプを表している。
Linux のシステムコールが使用する書き込みルーチンは、そのパイプを記述する
file データ構造体によってポイントされたルーチンである。書き込み
ルーチンが書き込み要求を処理する際に利用する情報は、そのパイプを表す VFS
inode に保持された情報である。
[see: pipe_write(), in
fs/pipe.c]
パイプへ書き込もうとする全バイト量を保持するだけの空きが共有ページ上に存在し、
パイプが読み出しプロセスによってロックされていない場合、Linux は書き込み
プロセスのためにそのパイプをロックして、書き込まれるべきバイト列を書き込み
プロセスのアドレス空間から共有データページにコピーする。
パイプが読み出しプロセスによってロックされているか、データを保持する充分な空
きスペースが存在しない場合は、現在のプロセスがパイプの inode の待ち
行列上でスリープ状態にされ、スケジューラが呼び出されて、他のプロセスが実行
される。
書き込みプロセスは割り込み可能であるので、シグナルの受信が可能である。
書き込みプロセスは、データ書き込みのための充分なスペースが確保されるか
パイプのロックが解除されたときに、読み込みプロセスによってスリープ状態から
起こされる。
データが書き込まれるとき、パイプの VFS inode のロックは解除され、
その inode の待ち行列上でスリープ状態になっている読み出しプロセスがあれば、
読み出しプロセスもそれによって目を覚ます。
パイプからのデータの読み出しは、書き込みプロセスと非常によく似ている。
[see: pipe_read(), in
fs/pipe.c]
プロセスは、ブロッキングしない読み出し(non-blocking read)をすることも
許される。(それは、プロセスがファイルやパイプをオープンするときのモードに
依存する。)そして、その場合、読み出すべきデータがないか、パイプがロックされて
いる場合は、エラーが返される。これは、そのプロセスが実行を継続できることを
意味する。それ以外の方法として、パイプの inode の待ち行列上で休止して、書き込み
プロセスの終了を待つことも可能である。両方のプロセスがパイプ処理を終了する
と、パイプの inode とその共有データページとは破棄される。
Linux は、名前付きパイプもサポートしている。パイプは先入れ先出し(First In,
First Out)の原理で処理を行うので、名前付きパイプは FIFO とも呼ばれる。
パイプに書き込まれた最初のデータは、パイプから読み出される最初のデータとな
る。通常のパイプとは異なり、FIFO は一時的なオブジェクトではなく、ファイルシス
テム内の実体であり、mkfifo コマンドによって作成が可能である。
プロセスは、それに対する適切なアクセス権限を持つ限り、自由に FIFO を利用する
ことができる。FIFO をオープンする方法は、通常のパイプのそれとは少し異なる。
通常のパイプ(ふたつの file データ構造体、VFS inode とその共有データ
ページのセット)は必要に応じて一時的に作成されるだけだが、FIFO はすでに
存在する実体であり、ユーザによってオープンされ、クローズされる。Linux は、
書き込みプロセスが FIFO をオープンする前に読み出しプロセスにそれをオープンさ
せ、書き込みプロセスがそれに書き込んでしまう前に読み出しプロセスがそれを読める
状態にするよう、それらを操作しなければならない。しかし、そうした
ことを除くと、FIFO の処理は、通常のパイプの処理方法とほとんど全く同一であり、
両者は同じデータ構造と処理メカニズムを使っている。
REVIEW NOTE: Add when networking chapter written.
Linux は、Unix System V (1983) で初めて登場したプロセス間通信(IPC)の仕組み を 3 種類サポートしている。それらは、メッセージキュー(message queue)、セマフォ (semaphore)、そして共有メモリ(shared memory)である。これらの System V IPC の 仕組みはすべて共通の認証方法を利用している。プロセスが共有リソースに アクセスできるのは、システムコール経由でカーネルに対してユニークな参照識別子 (reference identifier)を渡した場合だけである。 これらの System V IPC オブジェクトへのアクセスをチェックする 場合には、アクセスパーミッションが使用されるが、それはファイルへのアクセス チェックに類似したものである。System V IPC オブジェクトへのアクセス権限は、 そのオブジェクトの作成者によってシステムコール経由で設定される。個々の IPC メカニズムは、オブジェクトの参照識別子を、リソーステーブルへのインデックスと して利用している。しかし、それは単純なインデックスではなく、そのインデックス 作成には多少の操作を必要とする。
Linux システム上で System V IPC オブジェクトを表すすべてのデータ構造には、
ipc_perm 構造体が含まれている。そして、
その構造体には、そのオブジェクトの所有プロセスおよび作成プロセスのユーザ ID
とグループ ID とが含まれる。
[see:
include/linux/ipc.h]
また、ipc_perm には、そのオブジェクトへのアクセスモード(所有者、
グループ、その他)と IPC オブジェクトキー(
key)も含まれている。
キーは、System V IPC オブジェクトの参照識別子を探す手段として使用される。
サポートされているキーには、プライベート(private)とパブリック(public)の二種類
がある。キーがパブリックの場合、どのようなプロセスでも、アクセス権をチェック
された後、その System V IPC オブジェクトの参照識別子を見つけることができる。
System V IPC オブジェクトは、キーでは参照できないようになっていて、その参照
識別子でのみ参照が可能となっている。
メッセージキュー(message queue)とは、ひとつ以上のプロセスがメッセージを書
き込んで、それをひとつ以上の読み出しプロセスによって読み出すことを可能にする
仕組みである。Linux は、メッセージキューのリストを
msque 配列によって管理している。この配列の個々の要素は、
msqid_ds データ構造体をポイントしてい
て、その構造体が個々のメッセージキューを完全に記述している。メッセージキューが
作成されるとき、新しい msqid_ds データ構造体がシステムメモリから割り
当てられ、配列のなかに挿入される。
[see:
include/linux/msg.h]
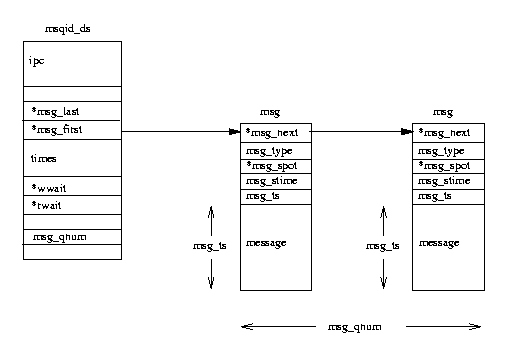
図表(5.2)System V IPC メッセージキュー
個々の
msqid_ds 構造体には、
ipc_perm データ構造体とそのキューに入れられた
メッセージへのポインタが含まれている。さらに、Linux は、キューの変更時間を記録
しており、たとえばそのキューに書き込みがなされた最後の時間といった情報を保持
している。msqid_ds には、ふたつの待ち行列が含まれていて、それぞれ
メッセージキューへの書き込みプロセスに対するものと読み出しプロセスに対する
ものとなっている。
プロセスが書き込みキューにメッセージを書き込もうとするときはいつも、その
実効ユーザ ID と実効グループ ID とが、そのキューの ipc_perm データ
構造体にあるモードと比較される。
プロセスがそのキューに書き込み可能な場合、メッセージは、そのプロセスのアドレ
ス空間から
msg データ構造体へとコピーされ、そ
のメッセージキューの最後に置かれる。個々のメッセージには、協調するプロセス間で
合意されたアプリケーション固有のタイプ(type)がタグ付けされる。しかし、Linux
は、書き込み可能なメッセージの数と長さを制限しているので、メッセージの書き込み
の際に容量が足りない場合が生じ得る。その場合、そのプロセスが当該メッセージ
キューの書き込みキューに加えられ、スケジューラが呼び出されて、新しいプロセス
が実行される。そして、いくつかのメッセージがそのメッセージキューから読み出さ
れたときに、先ほどのプロセスが起こされる。
キューからの読み出しも同様の過程を辿る。再度、書き込みキューに対するプロセ スのアクセス権がチェックされる。読み出しプロセスは、メッセージのタイプに関係 なくキューの最初のメッセージを取得するか、特定のタイプのメッセージを選択する かのいずれかを選択することができる。選択基準に合致するメッセージがない場合、 読み出しプロセスはメッセージキューの読み出し待ち行列に加えられて、スケジュー ラが実行される。新しいメッセージがキューに書き込まれると、そのプロセスは起こ されて再び実行される。
最も単純な形式で考えると、セマフォとは、複数のプロセスにより、ある値をテスト (test)したりセット(set)したりすることが可能な、メモリ上の場所である。 テストとセットの操作は、個々のプロセスに関する限り、割り込みができない、もし くは他のプロセスから干渉を受けない(atomic)操作である。すなわち、いったんプロ セスが操作を始めると他のプロセスがそれを止めることはできない。テストとセット の操作の結果は、そのセマフォの現在の値とセットした値との和となる。セットされ る値は、正の場合も負の場合もある。テストとセットの操作の結果によっては、ある プロセスが、他のプロセスによってセマフォの値が変更されるまで、休止しなければ ならない場合が起こる。セマフォは、非常に重要なメモリ領域を作成したいときに 利用することができ、一度に単一のプロセスだけが実行すべき非常に重要なコードの 領域を作り出すことができる。
たとえば、協調して働く多くのプロセスがあり、それらは単一のファイルを読み込 んだり、それに書き込んだりしているとする。そして、そのファイルへのアクセスを 厳しく調整したいと思っているとする。その場合、セマフォを使い、初期値を 1 に 設定し、ファイル操作コードの中に、ふたつのセマフォ操作コードを加える。ひとつ は、セマフォの値をテストして、その値から 1 を引くもの、もうひとつは、セマフォ 値をテストして値に 1 を足すものである。 ファイルにアクセスする最初のプロセスは、セマフォの値から 1 を引こうとし、それに 成功すればセマフォの値は 0 になる。このプロセスは処理を続けて、データファイル を使用するが、もし次のプロセスがそれを使いたいと思ってセマフォの値から 1 を引こ うとしても、その結果が -1 になってしまうので失敗する。 そのプロセスは、最初のプロセスがデータファイルの使用を終えるまで、停止状態に なる。最初のプロセスがデータファイルの使用を終えたら、セマフォの値に 1 を足 して、1 に戻す。この時点で、待機していたプロセスが起こされて、今回はセマフォ値 に 1 を足す(訳注: -1 か?)ことに成功する。
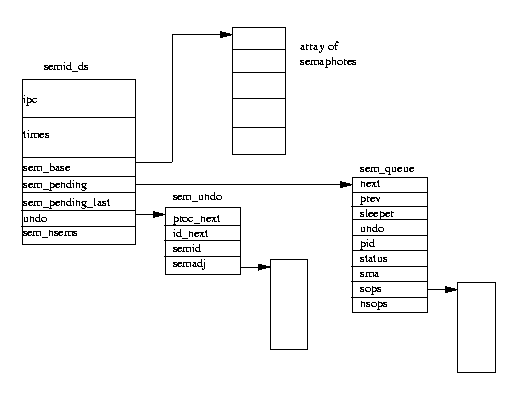
図表(5.3)System V IPC セマフォ
System V IPC セマフォオブジェクトは、それぞれがセマフォ配列を記述しており、
Linux は、
semid_ds データ構造体を使用して
これを表現する。
[see
include/linux/sem.h]
システム上のすべての semid_ds データ構造体は、
semary というポインタの配列によってポイントされている。
個々のセマフォ配列には、
sem_nsems 個の
要素があり、各々のセマフォ配列の要素は、
sem
データ構造体により記述されていて、sem 構造体は
sem_base によってポイントされている。
System V IPC セマフォオブジェクトから成るセマフォ配列の操作を許されているすべて
のプロセスは、システムコールを生成して、それらを操作する。
システムコールは多くの操作を指定することができるが、個々の操作は、セマフォ
インデックス(semaphore index)、オペレーション値(operation value)、および一連の
フラグ(a set of flag)という 3 つの入力項目によって記述される。
セマフォインデックスとは、セマフォ配列へのインデックスであり、オペレーション
値とは、セマフォの現在の値に加えるべき数値である。
Linux はまず、すべての操作が成功したかどうかをテストする。操作が成功するのは、
セマフォの現在の値にオペレーション値を加えた値がゼロより大きいか、もしくは
オペレーション値とセマフォの現在の値の両方がゼロの場合のいずれかである。
セマフォ操作がひとつでも失敗した場合で、他のプロセスをブロックしない
(non-blocking)システムコールをオペレーションフラグが要求しない場合、Linux は、
プロセスをサスペンドする。
プロセスがサスペンド状態になると、Linux は実行されるべきセマフォ操作の状態
(state)を保存して、現在のプロセスを待ち行列(wait queue)上に置かなければなら
ない。
その処理は、スタックに
sem_queue データ
構造体を作成して、必要な情報を書き込むことによってなされる。新しい sem_queue データ構造体は、そのセマフォオブジェクトの待ち行列の最後に置か
れる。(その際は、
sem_pending と
sem_pending_last ポインタが使用される。)
現在のプロセスは、sem_queue データ構造体の待ち行列上に(休止状態で)置
かれ、スケジューラが呼び出されて、次のプロセスが実行される。
もしセマフォ操作がすべて成功し、現在のプロセスを停止させる必要がなければ、
Linux は処理を継続し、セマフォ配列の適切なメンバーにその操作を適用する。
この時点で、Linux は、待ち状態や停止状態にあるプロセスがそれぞれのセマフォ
操作を適用できるかどうかをチェックする。Linux は、操作ルーチンのペンディング
キュー(pending queue)(
sem_pending)のメン
バーそれぞれを順番に見て、今回はそのセマフォ操作が成功するかどうかをテスト
する。
成功した場合、Linux は、ペンディングリストからその sem_queue データ
構造体を削除して、セマフォ配列にそのセマフォ操作を適用する。
Linux は、休眠中のプロセスを起こして、次にスケジューラが実行されるときに再始動
されるようにする。Linux は、ペンディングリストを最初から順に調べていって、
適用できるセマフォ操作が無くなり、それ以上プロセスを起こせなくなるまで
それを続ける。
セマフォには、デッドロックという問題がある。それが起こるのは、あるプロセス
が、重要なメモリ領域に入ったときのに、クラッシュするか kill されるかしてそこ
から出られなくなり、セマフォ値が変更されたままになる場合である。Linux はこれを
防止するために、セマフォ配列に対する調整(adjustment)リストを管理している。
そのアイデアは、セマフォ配列に調整が適用されると、セマフォが、問題を起こした
プロセスの操作が適用される前の状態(state)に戻されるということである。
これらの調整は、
sem_undo データ構造体に
保存されていて、それは
semid_ds データ
構造体上のキューとそれらのセマフォ配列を使うプロセスの
task_struct データ構造体上のキューとに置かれる。
個々のセマフォ操作は、調整のためのデータ管理がなされるされることを個別に要求
する場合がある。Linux は、個々のセマフォ配列について、プロセスあたり最大ひと
つの
sem_undo データ構造体しか管理しない。
調整を要求するプロセスがそれをひとつも持っていない場合は、必要なときにひとつの
データ構造体が作成される。新しい
sem_undo データ構造体は、そのプロセスの
task_struct データ構造体上のキューと、セマフォ配列の
semid_ds データ構造体上のキューとに入れられる。
セマフォ操作がセマフォ配列のセマフォに対して適用されるとき、オペレーション値
を正負逆にした値が、そのプロセスの sem_undo データ構造の調整
(adjustment)配列の中にあるセマフォエントリーに加えられる。
それゆえ、オペレーション値が 2 の場合、-2 がそのセマフォの調整エントリに加え
られる。
プロセスが終了して削除されるとき、Linux は、そのプロセスの
sem_undo データ構造体のセットを調査して、
セマフォ配列に対する調整を適用する。セマフォセットが削除された場合、sem_undo データ構造体は、プロセスの
task_struct のキューに残ったままになるが、セマフォ配列の識別子は
無効になる。その場合、セマフォを片づける(clean up)コードが、単にその sem_undo 構造体を破棄する。
共有メモリ(shared memory)は、プロセスの仮想アドレス空間の任意の場所を経由 して、複数のプロセスが通信することを可能にする仕組みである。共有される仮想メ モリのページは、個々の共有プロセスのページテーブル内にあるページテーブルエン トリによって参照される。 共有されるページは、すべてのプロセスの仮想メモリ内の同一アドレスになくてもよ い。System V IPC のオブジェクトを使う場合はすべて、共有メモリエリアへのアクセ スは、キーとアクセス権限のチェックによって制御されている。(正当なアクセスに より)いったんメモリが共有されたなら、プロセスがそれを使用する方法はチェック されない。メモリへのアクセスの同期を取るといったことは、他の仕組み、たとえば、 System V のセマフォなどの仕組みに依存しなければならない。
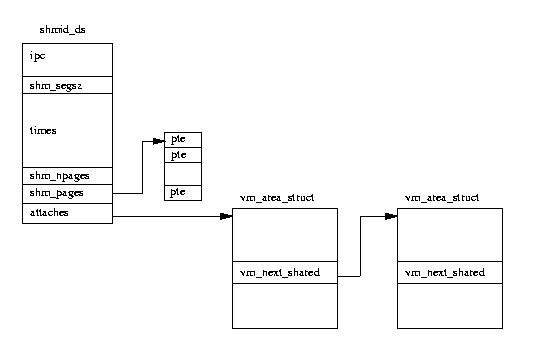
図表(5.4) System V IPC 共有メモリ
新しく作成された個々の共有メモリエリアは、
shmid_ds データ構造体によって表される。
それらは、
shm_segs 配列に保存される。
[see: include/linux/sem.h](訳注:
include/linux/shm.h?)
shmid_ds データ構造体は、その共有メモリのエリアの大きさ、それを使用
するプロセスの数、およびその共有メモリがプロセスのアドレス空間にマップされて
いる様子に関する情報を記述している。そのメモリへのアクセス権限や、
キーがパブリックキーかプライベートキーかを管理するのは、その共有メモリの作成者
である。プロセスが適切なアクセス権を持っているなら、共有メモリを物理メモリに
ロックすることもできる。
メモリを共有しようとする個々のプロセスが、自己の仮想メモリに共有領域を張り
付ける(attach)場合は、システムコールを利用しなければならない。そして、そのシ
ステムコールによって
vm_area_struct
データ構造体が作成され、それがプロセスの共有メモリを記述する。
プロセスは、共有メモリが自分の仮想アドレス空間内のどこに置かれるかを選択する
ことができるが、充分な広さの空領域の確保を Linux に任せることもできる。
新しい vm_area_struct 構造体は、vm_area_struct のリストに
挿入され、
shmid_ds によってポイントされ
る。
vm_next_shared と
vm_prev_shared ポインタが、それらをリンクす
るために使用される。共有メモリ領域は、仮想メモリに張り付けられた(attach)だけ
で実際に物理メモリ上に作成されるわけではない。プロセスが最初にそこにアクセス
しようとしたとき、初めて作成される。
初めてプロセスが共有メモリのページのひとつにアクセスしたときは、ページ
フォルトが発生する。Linux がそのページフォルトを解消したとき、プロセスは、
共有メモリを記述する
vm_area_struct
データ構造体を発見する。その構造体には、その共有メモリのタイプに合わせた処理
ルーチンへのポインタが含まれている。共有メモリページフォルト処理コードは、
その
shmid_ds に対するページテーブルエン
トリのリストを探して、共有仮想メモリの該当ページに関するエントリがあるか
どうかを確認する。もし存在しないなら、物理ページを割り当てて、そのための
ページテーブルエントリを作成する。カレントプロセスのページテーブルにそのエン
トリが付け加わると同時に、shmid_ds にもそれが保存される。すなわち、
そうしておけば、このメモリにアクセスしようとする次のプロセスがページフォルト
を起こしたとき、共有メモリ処理コードはこの新しく作成された物理ページをそのプ
ロセスのために使用できるわけである。それゆえ、共有メモリにアクセスした最初の
プロセスが物理メモリ上にそれを割り当てたことで、他のプロセスによるそれ以後の
アクセスは、その物理ページをそれらのプロセスの仮想アドレス空間に付加するだけ
で済むようになる。
プロセスがもはや仮想メモリの共有を必要としなくなったとき、プロセスは自己の
仮想メモリからその領域を外す(detach)。他のプロセスがまだそのメモリを使用して
いる限り、外す(detach)操作はカレントプロセスだけにしか影響しない。その
vm_area_struct は、
shmid_ds データ構造体から削除され、解放される。
カレントプロセスのページテーブルがアップデートされ、共有されていた仮想メモリ
のエリアは無効にされる。メモリを共有していた最後のプロセスが共有メモリ領域を
外す(detach)とき、物理メモリにある共有メモリのページは解放され、その共有メモ
リに関する shmid_ds データ構造体も解放される。
共有仮想メモリが物理メモリにロックされないときは、さらに複雑なことが起こる。 その場合、共有メモリのページは、物理メモリの消費が激しい間は、システムのス ワップディスクにスワップアウトされる。共有メモリが物理メモリからスワップアウ トやスワップインされる方法は、 「メモリ管理」の章で解説している。
(脚注1)プロセスグループについて、説明すること。(訳注: 原文のままです。)