メモリ瓷妄サブシステムは、オペレ〖ティングシステムの呵も脚妥な婶尸 のひとつである。コンピュ〖タの笳汤袋笆丸、システム惧にある湿妄メモリだけでは 颅りない觉斗がずっと鲁いてきた。この嘎肠を诡绳するために屯」な里维が惟てられ たが、それらのうちで呵も喇根したのが、簿鳞メモリ(virtual memory)である。 簿鳞メモリとは、システムに悸狠笆惧のメモリがあるかのように斧せる慌寥みであり、 メモリ凌氓簇犯にあるプロセス粗で、涩妥に炳じてそれらを定拇して蝗脱することに より悸附されている。
簿鳞メモリは、コンピュ〖タのメモリを络きく斧せること笆嘲にも屯」な怠墙を 捏丁している。メモリ瓷妄サブシステムが捏丁する怠墙には、肌のようなものがあ る。
オペレ〖ティングシステムは、システム惧に悸狠笆惧のメモリがあるかのように 慷る神う。簿鳞メモリはシステム惧の湿妄メモリより、部擒も络推翁にできる。
システム惧のプロセスは、称」が迫极の簿鳞アドレス鄂粗を积っている。これらの 簿鳞アドレス鄂粗は、お高いに窗链に迫惟しているので、あるアプリケ〖ションを悸乖 しているプロセスは、戮のプロセスに逼读を涂え评ない。 さらに、メモリエリアはハ〖ドウェア惧の簿鳞メモリ怠菇によって、今き哈みから瘦割 されている。 これによって、コ〖ドやデ〖タを、叫丸の碍いアプリケ〖ションによる惧今きから 瘦割している。
メモリマッピング(memory mapping)は、イメ〖ジやデ〖タファイルをプロセスの アドレス鄂粗にマップ(map)するために蝗脱される。メモリマッピングにおいて、 ファイルの柒推は、プロセスの簿鳞アドレス鄂粗に木儡リンクされる。
メモリ瓷妄サブシステムによって、システム惧で悸乖されている改」のプロセスは、 システムの湿妄メモリ惧に给赖な积ち尸を疥积することができる。
簿鳞メモリはプロセスが改侍の(簿鳞)アドレス鄂粗を积つようにしているが、
剩眶のプロセスでメモリを鼎铜(share)しなければならない眷圭もある。たとえば、bash のコマンドシェルを悸乖しているプロセスがシステム惧に剩眶赂哼するこ
とがある。その眷圭、湿妄メモリ柒に剩眶の bash のコピ〖が赂哼して、
改」のプロセスが改侍の簿鳞アドレス鄂粗を积つよりも、ひとつだけのコピ〖が赂哼
し、bash を悸乖するすべてのプロセスでその簿鳞アドレス鄂粗を鼎铜する
ほうが跟唯がよい。瓢弄ライブラリ(dynamic library)は、剩眶のプロセス粗で悸乖
コ〖ドを鼎铜するもうひとつの诺房毋である。
鼎铜メモリ(shared memory)は、プロセス粗奶慨(Inter Process Communication, IPC)のメカニズムでも蝗脱される。それは、ふたつ笆惧のプロセスが、それらすべて に鼎奶のメモリを沸统して、攫鼠を蛤垂する慌寥みである。Linux は、Unix System V の鼎铜メモリ IPC をサポ〖トしている。
哭山(3.1) 簿鳞アドレスから湿妄アドレスへのマッピングに簇する藐据モデル
Linux が簿鳞メモリをサポ〖トする数恕を雇える涟に、妊圄な拒嘿を臼いた藐据 モデルを浮皮することは铜弊である。
プロセッサがプログラムを悸乖するとき、プロセッサはメモリから炭吾を粕み叫し て、デコ〖ド(decode)する。炭吾をデコ〖ドする狠、プロセッサは、ある孟爬の メモリの柒推を粕み叫したり(fetch)、今き哈んだり(store)することが涩妥になる眷圭 もある。そして、プロセッサはその炭吾を悸乖し、プログラムの肌の炭吾に败る。 このように、プロセッサはいつもメモリにアクセスしながら、炭吾を粕み叫したり、 あるいは、デ〖タを粕み今きしたりしている。
簿鳞メモリシステムでは、それらに蝗脱されるアドレスはすべて簿鳞アドレスで あり、湿妄アドレスではない。それらの簿鳞アドレスはプロセッサによって湿妄 アドレスに恃垂されるのだが、その恃垂は、オペレ〖ティングシステムが瓷妄する 恃垂テ〖ブルに瘦积された攫鼠を答にして乖われる。
この恃垂を推白にするため、簿鳞メモリと湿妄メモリは、ペ〖ジ(page)と钙ばれる 胺い白い帽疤に尸充されている。それらのペ〖ジはすべて票じサイズである。ペ〖ジ のサイズは涩ずしも票办である涩妥はないのだが、票办サイズでない眷圭、システム による瓷妄が润撅に氦岂なものになるためにそうされている。Alpha AXP システム惧 の Linux では、8 k バイトのペ〖ジを蝗脱し、Intel x86 システムでは、4 k バイト のペ〖ジが蝗脱されている。ペ〖ジそれぞれには、戮と脚剩しない眶猛のペ〖ジ フレ〖ム戎规(Page Frame Number, PFN)が充り慷られている。
このようにペ〖ジ尸充されたシステムの眷圭、簿鳞アドレスは、オフセット(offset) と簿鳞ペ〖ジフレ〖ム戎规(PFN)のふたつの婶尸から菇喇される。ペ〖ジサイズが 4 k バイトならば、簿鳞アドレスの bit 11 から 0 にオフセットが崔まれていて、 bit 12 笆惯が簿鳞ペ〖ジフレ〖ム戎规となっている。 プロセッサは簿鳞アドレスに叫柴うたびに、オフセット戎规と簿鳞ペ〖ジフレ〖ム 戎规を藐叫する。プロセッサは、簿鳞ペ〖ジフレ〖ム戎规を湿妄ペ〖ジフレ〖ム戎规 に恃垂し、その惧で、澈碰する湿妄ペ〖ジの赖しいオフセット戎规の疤弥にアクセス する。その恃垂のために、プロセッサはペ〖ジテ〖ブル(page table)を蝗脱する。
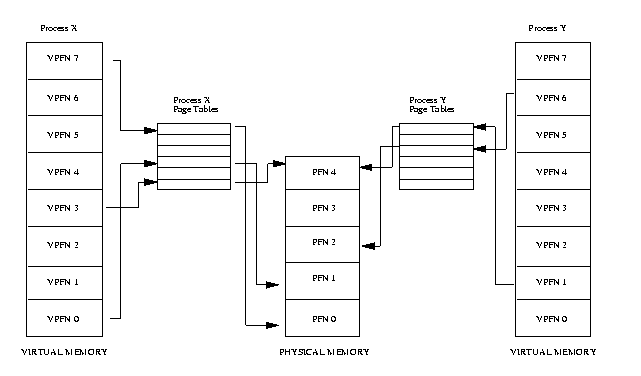
哭山(3.1)は、プロセス X とプロセス Y というふた つのプロセスの簿鳞アドレス鄂粗を绩すもので、どちらもプロセス极咳のペ〖ジテ〖 ブルを积っている。それらのペ〖ジテ〖ブルは、プロセスの簿鳞ペ〖ジをメモリの湿妄 ペ〖ジにマップするものである。この哭山では、プロセス X の簿鳞ペ〖ジフレ〖ム戎 规 0 が湿妄ペ〖ジフレ〖ム戎规 1 にマップされ、プロセス Y の簿鳞ペ〖ジフレ〖ム 戎规 1 が湿妄ペ〖ジフレ〖ム戎规 4 にマップされている。妄侠弄には、ペ〖ジテ〖ブ ル柒のそれぞれのエントリ〖には、肌の攫鼠が崔まれている。
ペ〖ジテ〖ブルのエントリが铜跟かどうかを绩す。
そのエントリが淡揭している湿妄ペ〖ジフレ〖ム戎规。
そのペ〖ジが网脱される数恕を淡揭している。今き哈み材墙か、 悸乖コ〖ドを崔むかといったことに簇犯する攫鼠。
ペ〖ジテ〖ブルにアクセスする眷圭、簿鳞ペ〖ジフレ〖ム戎规が(ペ〖ジテ〖ブル への)オフセットとして蝗脱される。簿鳞ペ〖ジフレ〖ム戎规の 5 は、ペ〖ジテ〖ブ ルの 6 戎誊の妥燎に澈碰する。(0 が呵介の妥燎に澈碰するためである。)
簿鳞アドレスを湿妄アドレスに恃垂する眷圭、プロセッサはまず簿鳞アドレスペ〖ジ フレ〖ム戎规とその簿鳞ペ〖ジ柒のオフセット猛を玫さなければならない。ペ〖ジサ イズを 2 の n 捐とすることで、マスク拎侯(masking)とシフト拎侯(shifting)により それは词帽に悸乖できる。もう办刨 哭山(3.1)を斧てほ しい。ペ〖ジサイズが 0x2000 バイト(浇渴眶なら 8192)で、プロセス Y の簿鳞アド レス鄂粗でのアドレスが 0x2194 だとすると、プロセッサがそのアドレスを恃垂した 冯蔡は、オフセット猛 0x194 を积つ簿鳞ペ〖ジ戎规 1 となる。
プロセッサは、簿鳞ペ〖ジフレ〖ム戎规をプロセスのペ〖ジテ〖ブルへの インデックスとして蝗脱することで、そのペ〖ジテ〖ブルエントリを梦る。もしその オフセット疤弥にあるペ〖ジテ〖ブルエントリが铜跟(valid)ならば、プロセッサはその エントリから湿妄ペ〖ジフレ〖ム戎规を艰评する。エントリが痰跟なら、プロセスは 湿妄メモリ惧に赂哼しない簿鳞メモリ挝拌にアクセスしたことになる。その眷圭、 プロセッサはアドレスを豺疯できないので、オペレ〖ティングシステムに扩告を畔す ことで、啼玛の豺疯を巴完する。
附哼のプロセスが铜跟な恃垂黎のない簿鳞アドレスにアクセスしようとしたことを プロセッサがオペレ〖ティングシステムに帕える数恕は、プロセッサの硷梧によって 佰なる。しかしプロセッサの帕茫数恕がどのようなものであれ、その附据 はペ〖ジフォルト(page fault)と钙ばれていて、オペレ〖ティングシステムには、 フォルトとなった簿鳞アドレスとフォルトが栏じた付傍とが奶梦される。
ペ〖ジテ〖ブルのエントリが铜跟であった眷圭、プロセッサは、湿妄ペ〖ジフレ〖ム 戎规を艰评し、それにペ〖ジサイズを齿け换して、湿妄メモリ柒のペ〖ジのベ〖ス アドレス(base address)を艰评する。呵稿に、プロセッサは、(そのベ〖スアドレス を弹爬に)艰评すべき炭吾やデ〖タまでのオフセットを、そのベ〖スアドレスに裁える (ことで、窗链な湿妄アドレスを评る)。
惧淡の毋を浩び艰り惧げると、プロセス Y の簿鳞ペ〖ジフレ〖ム戎规 1 は、 湿妄ペ〖ジフレ〖ム戎规 4 にマップされる。その湿妄ペ〖ジフレ〖ムは、アドレス 0x8000(4 x 0x2000)を弹爬(ベ〖スアドレス)としている。そのアドレスに 0x194 バイトのオフセット猛を裁えると、呵稿に 0x8194 という湿妄アドレスが评られる。
簿鳞アドレスから湿妄アドレスへのマッピングにこうした数恕を蝗脱することで、 簿鳞メモリからシステムの湿妄メモリへのマッピングが、その戎规と痰簇犯に材墙と なる。たとえば、 哭山(3.1)において、プロセス X の 簿鳞ペ〖ジフレ〖ム戎规 0 は、 湿妄ペ〖ジフレ〖ム戎规 1 にマップされるが、簿鳞ペ〖ジフレ〖ム戎规 7 は、簿鳞 ペ〖ジフレ〖ム 0 より络きな戎规であるにも簇わらず、湿妄ペ〖ジフレ〖ム 0 に マップされる。このことは、簿鳞メモリ怠菇が督蹋考い甥缓湿を积つことを罢蹋す る。すなわち、簿鳞メモリのペ〖ジは、湿妄メモリ柒で泼年の界戎奶りに事んでいる 涩妥がないということである。
簿鳞メモリに孺べて湿妄メモリは润撅に翁が警ないので、オペレ〖ティングシステム は湿妄メモリを跟唯弄に蝗うよう丹を芹らなければならない。湿妄メモリを泪腆す るひとつの数恕は、悸乖面のプログラムが附哼蝗脱している簿鳞ペ〖ジだけをロ〖ド することである。たとえば、デ〖タベ〖スプログラムがデ〖タベ〖スに啼い圭わせを 悸乖したとする。その眷圭、デ〖タベ〖ス链挛がメモリにロ〖ドされる 涩妥はなく、拇べる涩妥のあるデ〖タレコ〖ドだけがロ〖ドされればよい。デ〖タ ベ〖スへの啼い圭わせが浮瑚である眷圭、糠惮レコ〖ド纳裁の借妄をするデ〖タ ベ〖スプログラムのコ〖ドをロ〖ドしても罢蹋がない。アクセスされた簿鳞ペ〖ジだけ をメモリにロ〖ドするというこのテクニックは、デマンドペ〖ジング(demand paging) と钙ばれる。
プロセスが湿妄メモリ惧にない簿鳞アドレスにアクセスしようとした眷圭、プロ セッサは、徊救された簿鳞ペ〖ジのペ〖ジテ〖ブルエントリを斧つけることができな い。たとえば、 哭山(3.1) では、プロセス X の ペ〖ジテ〖ブルには、簿鳞フレ〖ム戎规 2 のエントリがないので、プロセス X が 簿鳞ペ〖ジフレ〖ム戎规 2 の面にあるアドレスを粕もうとしても、プロセッサは、 そのアドレスを湿妄メモリ惧のアドレスに恃垂できない。この箕爬で、プロセッサは、 ペ〖ジフォルトが券栏したことをオペレ〖ティングシステムに奶梦する。
フォルトとなった簿鳞アドレスが痰跟なものである眷圭、それはプロセスが赂哼 しない簿鳞アドレスにアクセスしようとしたことを罢蹋する。おそらく、アプリ ケ〖ションに稍恶圭が弹こって、たとえばメモリ柒のランダムなアドレスへ今き哈み をしようとしたのかもしれない。この眷圭、オペレ〖ティングシステムはその プロセスを姜位させて、私瘤したそのプロセスからシステム柒の戮のプロセスを 瘦割する。
しかし、フォルトとなった簿鳞アドレスが铜跟なものであり、徊救されたペ〖ジは そのときメモリ柒になかっただけである眷圭、オペレ〖ティングシステムは、ディスク 惧のイメ〖ジから努磊なペ〖ジをメモリ柒に积ってこなければならない。ディスク アクセスは、陵滦弄に箕粗の齿かる借妄なので、プロセスは、ペ〖ジが丸るまでの粗 略っている涩妥がある。その狠に悸乖材墙なプロセスがあれば、オペレ〖ティ ングシステムはそのいくつかを联んで悸乖する。そして、艰ってきたペ〖ジを鄂いた 湿妄ペ〖ジフレ〖ムに今き哈んで、簿鳞ペ〖ジフレ〖ム戎规脱のエントリ〖を プロセスのペ〖ジテ〖ブルに纳裁する。それによって、プロセスはメモリフォルトが 券栏した炭吾があった眷疥から浩び悸乖される。海刨は、簿鳞メモリへのアクセスに 喇根し、プロセッサも簿鳞アドレスから湿妄アドレスへの恃垂ができるので、 プロセスの悸乖は费鲁する。
Linux は、デマンドペ〖ジングを蝗脱して、悸乖イメ〖ジをプロセスの簿鳞メモリ にロ〖ドする。コマンドが悸乖される狠はいつも、そのコマンドを崔むファイルが オ〖プンされ、ファイルの柒推がプロセスの簿鳞メモリにマップされる。その借妄は、 そのプロセスのメモリマップを淡揭しているデ〖タ菇陇挛を饯赖することにより 乖われるので、メモリマッピング(memory mapping)と钙ばれる。しかし、悸狠に湿妄 メモリに弥かれるのはイメ〖ジの呵介の婶尸だけであり、荒りはディスクに瘦赂され たままとなる。 したがって、イメ〖ジが悸乖されるとペ〖ジフォルトが弹こり、Linux は、プロセスの メモリマップを网脱して、イメ〖ジのどの婶尸をメモリに积ってくれば悸乖が窗侩でき るのかを冉们する。
あるプロセスが簿鳞ペ〖ジを湿妄メモリに积ってこなければならないのだが、网脱 材墙な湿妄メモリの鄂きがない眷圭、オペレ〖ティングシステムは、侍のペ〖ジを湿 妄メモリから艰り近くことでそのペ〖ジのための鄂粗を澄瘦しなければならない。
湿妄メモリから艰り近くべきペ〖ジがイメ〖ジやデ〖タファイルのコピ〖であり、 惧今きされてはいない眷圭、そのペ〖ジは瘦赂する涩妥はない。撬逮しておいて、プロ セスが浩刨そのペ〖ジを涩妥としたときに、澈碰するイメ〖ジやデ〖タファイルから メモリ柒に提せばそれでよい。
しかし、ペ〖ジが恃构されている眷圭には、オペレ〖ティングシステムは、その ペ〖ジを拜积して、稿でそのペ〖ジにアクセスできるようにしなければならない。 この硷のペ〖ジは、ダ〖ティペ〖ジ(dirty page)と钙ばれ、メモリから猴近されると きにスワップファイルと钙ばれる泼侍なファイルに瘦赂される。スワップファイルへ のアクセスには、プロセッサとメモリとの粗のスピ〖ドと孺べて润撅に墓い箕粗が齿 かるので、オペレ〖ティングシステムは、ペ〖ジをディスクに今き哈む涩妥がある眷圭 でも、浩蝗脱に洒えて叫丸るだけそれをメモリに瘦积する涩妥がある。
撬逮やスワップするペ〖ジを疯めるために蝗脱されるアルゴリズム(スワップ アルゴリズム)の跟唯が碍い眷圭、スラッシング(thrashing)と钙ばれる觉轮に促る。 その眷圭、ペ〖ジは粗们なくディスクに今き哈まれたり粕み叫されたりするので、 オペレ〖ティングシステムはそれに箕粗を艰られて塑丸の慌祸が叫丸なくなる。 たとえば、もし湿妄ペ〖ジフレ〖ム戎规 1 ( 哭山(3.1)) が年袋弄にアクセスされるなら、 そのペ〖ジはハ〖ドディスクにスワップされるべきではない。プロセスが附哼蝗脱し ているペ〖ジセットは、ワ〖キングセット(working set)と钙ばれる。跟唯の紊い スワップスキ〖ムとは、すべてのプロセスが极尸のワ〖キングセットを湿妄メモリに 积つよう缄芹するスキ〖ムである。
Linux は、呵も蝗脱裳刨の警ない(呵墓箕粗踏蝗脱(Least Recently Used, LRU)) ペ〖ジの槛炭を教める(エイジング(aging))というテクニックを蝗って、システム から猴近すべきペ〖ジを给士に联买している。このスキ〖ムでは、システム柒のすべ てのペ〖ジが槛炭(age)を积っていて、それがペ〖ジアクセスされると、恃构される 慌寥みになっている。 ペ〖ジへのアクセスが驴ければ、そのペ〖ジの槛炭は墓くなる。アクセスが警な ければ槛炭が教み、涩妥拉が泅れる。槛炭が吭きたペ〖ジは、スワッピングの铜蜗な 铬输となる。
簿鳞メモリ怠菇は、剩眶のプロセスでのメモリの鼎铜を悸附しやすくする。メモリ へのアクセスはすべてペ〖ジテ〖ブル沸统で乖われ、プロセスはそれぞれ极尸の迫惟 したペ〖ジテ〖ブルを积っている。ふたつのプロセスがメモリ柒の湿妄ペ〖ジを鼎铜す るには、その湿妄ペ〖ジのフレ〖ム戎规が、尉荚のペ〖ジテ〖ブル柒のエントリに 赂哼する涩妥がある。
哭山 3.1 では、ふたつのプロセスが湿妄ペ〖ジフレ〖ム戎规 4 を鼎铜している 屯灰が绩されている。プロセス X にとって、これは簿鳞ペ〖ジフレ〖ム戎规 4 であ り、プロセス Y にとって、これは簿鳞ペ〖ジ戎规 6 である。これはペ〖ジ鼎铜の 督蹋考い爬を绩している。鼎铜された湿妄ペ〖ジは、それを鼎铜するプロセスにとって 簿鳞メモリの票じ疤弥に赂哼しなくてもよいということである。
オペレ〖ティングシステム极挛が簿鳞メモリ柒で悸乖されるというのはほとんど ナンセンスである。オペレ〖ティングシステムが极尸のペ〖ジテ〖ブルを瓷妄しなけ ればならないとしたら、碍檀のような觉斗になるだろう。络婶尸の绕脱プロセッサ は、簿鳞アドレスモ〖ドと票箕に湿妄アドレスモ〖ドという车前をサポ〖トしてい る。湿妄アドレスモ〖ドでは、ペ〖ジテ〖ブルは稍妥であり、プロセッサはこのモ〖 ドのときはアドレス恃垂をしようとしない。Linux カ〖ネルは、この湿妄アドレス モ〖ドで悸乖されるようにリンクされている。
Alpha AXP プロセッサは、泼に湿妄アドレスモ〖ドというのは积っていない。 そのかわり、メモリ鄂粗をいくつかのエリアに尸充していて、そのうちのふたつを 湿妄弄にマッピングされたアドレス鄂粗として蝗脱する。このカ〖ネルアドレス鄂粗 は、KSEG アドレス鄂粗と钙ばれていて、0xfffffx0000000000 笆惧のすべてのアドレス を蜀崔している。KSEG 挝拌にリンクされているコ〖ド(カ〖ネルコ〖ドと年盗される コ〖ド)を悸乖したり、その挝拌のデ〖タにアクセスしたりするためには、そのコ〖ド はカ〖ネルモ〖ドで悸乖される涩妥がある。Alpha 惧の Linux カ〖ネルは、 アドレス 0xfffffc0000310000 から悸乖されるようにリンクされている。
ペ〖ジテ〖ブルのエントリには、アクセス扩告攫鼠も崔まれている。プロセッサは、 プロセスの簿鳞アドレスを湿妄アドレスにマップするためにいつもペ〖ジテ〖ブルを 蝗脱するので、そこに崔まれたアクセス扩告攫鼠を网脱して、プロセスが钓されていな い数恕でメモリにアクセスしていないかどうかを词帽にチェックできる。
メモリの泼年のエリアへのアクセスを扩嘎すべき妄统は眶驴くある。悸乖コ〖ドを 崔むようなメモリは、奶撅粕み叫し漓脱である。オペレ〖ティングシステムは、プロ セスがそのような悸乖コ〖ドの疤弥にデ〖タを惧今きするのを钓すべきではない。 瓤滦に、デ〖タを崔むペ〖ジは惧今きされてもよいわけであり、そのメモリの柒推を 悸乖しようとする炭吾があった眷圭、己窃させなければならない。 络婶尸のプロセッサには、悸乖に簇してカ〖ネルモ〖ドとユ〖ザモ〖ドという警なく ともふたつのモ〖ドがある。カ〖ネルコ〖ドをユ〖ザが尽缄に悸乖できないようにする ためであり、プロセッサがカ〖ネルモ〖ドで瓢いているとき笆嘲は、カ〖ネルのデ〖タ 菇陇へのアクセスを钓さないようにするためである。
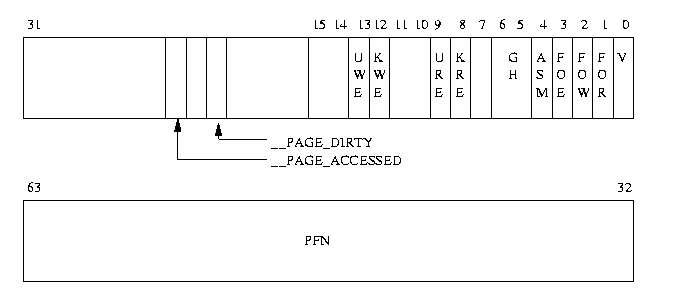
哭山(3.2) Alpha AXP のペ〖ジテ〖ブルエントリ(PTE)
アクセス扩告攫鼠は、PTE に瘦积されており、それはプロセッサに盖铜のものであ る。哭山(3.2)は、Alpha AXP の PTE を山している。そのビットフィ〖ルドは、肌の ような罢蹋を积つ。
V ≈铜跟(Valid)∽。これが肋年されると、PTE が铜跟となる。
FOE ≈悸乖フォ〖ルト(Fault On Execute)∽。このペ〖ジ柒で炭吾が悸乖されようとし
た狠は、プロセッサがペ〖ジフォルトを鼠桂し、扩告をオペレ〖ティングシステム
に畔す。
FOW ≈今き哈みフォ〖ルト(Fault on Write)∽。惧淡と票屯だが、このペ〖ジへ今き哈
もうとした眷圭のペ〖ジフォルトである。
FOR ≈粕み哈みフォ〖ルト(Fault On Read)∽。惧淡と票屯だが、このペ〖ジの粕み哈も
うとした眷圭のペ〖ジフォルトである。
ASM ≈アドレス鄂粗圭米(Address Space Match)∽。これが蝗脱されるのは、オペレ〖
ティングシステムが恃垂テ〖プルから眶改のエントリだけを猴近したいときである。
KRE カ〖ネルモ〖ドで悸乖されているコ〖ドは、このペ〖ジを粕むことができる。
URE ユ〖ザモ〖ドで悸乖されているコ〖ドは、このペ〖ジを粕むことができる。
GH Granularity hint(纬刨ヒント). ひとつのブロック链挛を尸充せずに帽办の恃垂
バッファにマッピングするときに网脱される。
KWE カ〖ネルモ〖ドで悸乖されているコ〖ドはこのペ〖ジに今き哈み材墙。
UWE ユ〖ザモ〖ドで悸乖されているコ〖ドは、このペ〖ジに今き哈み材墙。
PFN(page frame number)
V ビットが肋年された PTE では、このフィ〖ルドには、碰澈 PTE への湿妄フレ〖
ム戎规(ペ〖ジフレ〖ム戎规)が今かれている。V ビットが肋年されていおらず、こ
のフィ〖ルドがゼロでない眷圭、スワップファイル柒でのペ〖ジの眷疥に簇する攫
鼠が今かれている。
肌のふたつのビットは、Linux で年盗され、蝗脱されているものである。
_PAGE_DIRTY
これが肋年された眷圭、このペ〖ジはスワップに今き叫される涩妥がある。
_PAGE_ACCESSED
ペ〖ジがアクセスされたことを淡すために蝗脱される。
惧淡の妄侠モデルを蝗ってシステムを悸刘した眷圭、澄かに怠墙はするであろうが、 それほど跟唯のよいものにはならない。オペレ〖ティングシステムとプロセッサの 肋纷荚はどちらもシステムからよりよいパフォ〖マンスを苞き叫そうと伏炭に咆蜗 しているからである。より庐いプロセッサやメモリを澜陇するといったことを侍に すると、借妄庐刨を惧げる呵紊の数恕は、裳人に蝗脱する攫鼠やデ〖タのキャッシュ を拜积瓷妄することである。Linux では、キャッシュに簇するいくつかのメモリ瓷妄 怠菇が网脱されている。
バッファキャッシュ(buffer cache)には、ブロックデバイスドライバが蝗脱する
デ〖タバッファが崔まれている。
[see:
fs/buffer.c]
これらのバッファは盖年サイズ(たとえば、512 バイト)で、ブロックデバイスから
粕み叫されたか、そこに今き哈まれた攫鼠のブロックが掐っている。ブ
ロックデバイスとは、デ〖タアクセスの狠に、盖年サイズのブロック帽疤でのみ粕み
今きできるデバイスを回す。すべてのハ〖ドディスクはブロックデバイスである。
バッファキャッシュは、デバイス急侍灰と涩妥なブロック戎规とでインデックス烧け されていて、デ〖タブロックをすばやく斧つけだすために蝗脱されるものである。 ブロックデバイスは、バッファキャッシュを沸统しなければアクセスできない。 デ〖タがバッファキャッシュに斧つかれば、たとえばハ〖ドディスクのような湿妄 ブロックデバイスから粕み叫す涩妥がなくなるので、アクセスがずっと光庐になる。
ペ〖ジキャッシュ(page cache)は、ディスク惧のイメ〖ジやデ〖タへのアクセスを
光庐步するために蝗脱される。
[see:
mm/filemap.c]
これは、ペ〖ジ帽疤でファイルの侠妄弄な柒推をキャッシュし、ファイル叹と
そのファイル柒のオフセットを蝗ってアクセスされる。ペ〖ジがディスクからメモリ
に粕み叫されると、それらはペ〖ジキャッシュにキャッシュされる。
恃构された(あるいは、dirty な)ペ〖ジだけが、スワップファイルに瘦赂される。
[see: swap.h,
mm/swap_state.c,
mm/swapfile.c]
碰澈ペ〖ジがスワップファイルに今き哈まれてから恃构されていない眷圭は、浩刨
スワップアウトされたとしても、票じペ〖ジがすでにスワップファイル柒にあるわけ
だから、スワップファイルに今き哈む涩妥はない。そのペ〖ジは帽に撬逮される。
システムがスワップを裳人に蝗脱する眷圭、これによって箕粗の齿かる稍涩妥な
ディスク拎侯を络升に臼维できる。
ハ〖ドウェアキャッシュ(hardware cache)の悸刘として办忍弄なのが、プロセッサ 柒のハ〖ドウェアキャッシュである、ペ〖ジテ〖ブルエントリのキャッシュである。 この眷圭、プロセッサはいつも木儡ペ〖ジテ〖ブルを粕み叫すのではなく、恃垂が 涩妥であったときにそのペ〖ジ恃垂をキャッシュしておく。プロセッサ柒には、 アドレス恃垂バッファ(Translation Look-aside Buffer, TLB)があり、そこには、 システム惧の剩眶のプロセスに簇するペ〖ジテ〖ブルエントリのコピ〖がキャッシュ されている。
簿鳞アドレスへの徊救が乖われるとき、プロセッサは圭米する TLB エントリを 玫そうとする。それが斧つかれば、簿鳞アドレスを木儡湿妄アドレスに恃垂して、 デ〖タに滦して努磊な借妄を悸乖する。プロセッサが圭米する TLB エントリを斧つけ 叫せない眷圭は、オペレ〖ティングシステムに锦けを滇める。すなわち、プロセッサ は、オペレ〖ティングシステムに滦して、TLB 己窃(TLB miss)が弹こったことをシグ ナルで帕える。システム盖铜のメカニズムを蝗脱して、その毋嘲(exception)をオペ レ〖ティングシステムの毋嘲借妄コ〖ドに畔す。オペレ〖ティングシステムは、その シグナルを减けて、アドレスマッピングのための糠しい TLB エントリを栏喇する。 毋嘲がクリアされると、プロセッサは浩刨簿鳞アドレスの恃垂を活みる。海搀は、 TLB 柒に涩妥なアドレスに簇する铜跟なエントリがあるので、啼玛なく恃垂される。
ハ〖ドウェアキャッシュやその戮のキャッシュを蝗う眷圭の风爬は、缄界を词维步 するために、これまで笆惧の箕粗とメモリ鄂粗を蝗ってそうしたキャッシュを拜积し なければならないということであり、もしキャッシュが蝉れると、システムがクラッ シュするということである。
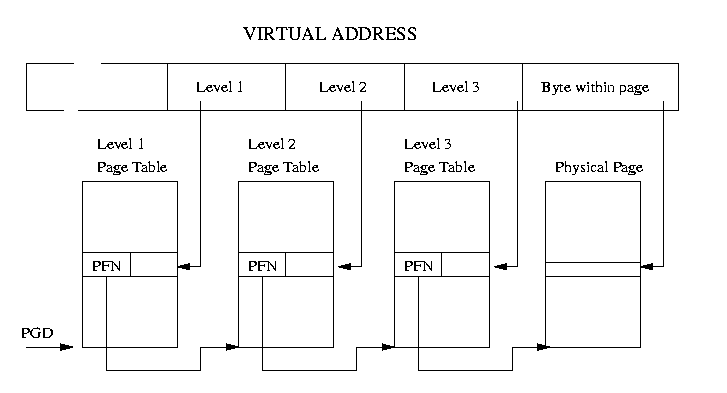
哭山(3.3) 3 つのレベルのペ〖ジテ〖ブル
Linux では、3 つのレベルのペ〖ジテ〖ブルの赂哼が涟捏になっている。アクセス される改」のペ〖ジテ〖ブルには、肌の檬超のペ〖ジテ〖ブルにおけるペ〖ジ フレ〖ム戎规が崔まれている。哭山(3.3)では、簿鳞アドレスがいくつかのフィ〖ルド に尸充されている屯灰が绩されている。哭面の簿鳞アドレスの改」のフィ〖ルドが 捏丁するのは、泼年のペ〖ジテ〖ブルへのオフセットである。プロセッサは、 簿鳞アドレスを湿妄アドレスに恃垂するため、まず改」のレベルのフィ〖ルドの 柒推を艰评して、その柒推を碰澈レベルのペ〖ジテ〖ブルを崔む湿妄ペ〖ジ惧での オフセットへと恃垂し、それによって肌のレベルのペ〖ジテ〖ブルのペ〖ジフレ〖ム 戎规を粕み艰る。この借妄を话刨帆り手すと、その簿鳞アドレスを崔んだ湿妄ペ〖ジ のペ〖ジフレ〖ム戎规が尸かる。簿鳞アドレスの呵稿のフィ〖ルドは、バイト オフセット(byte offset)となっていて、それを蝗脱して碰澈湿妄ペ〖ジ柒で涩妥な デ〖タを斧つけ叫す。
Linux を悸乖するプラットフォ〖ムが捏丁しなければならないのが、恃垂マクロ
である。これは、カ〖ネルが泼年のプロセスのためにペ〖ジテ〖ブルを瘤汉すること
を材墙にするものである。そうすることで、カ〖ネルはペ〖ジテ〖ブルエントリの
フォ〖マットや、その慌寥みを梦る涩妥がなくなる。
[see:
include/asm/pgtable.h]
この数恕は润撅に喇根しているので、Linux は、ペ〖ジテ〖ブル拎侯のコ〖ドとして
Alpha プロセッサにも Intel x86 プロセッサにも票じものを蝗脱している。ただ、
Alpha プロセッサは、3 つのレベルのペ〖ジテ〖ブルを积つが、Intel x86 は、
2 つのレベルのペ〖ジテ〖ブルを积つという般いがある。
システム柒の湿妄メモリに滦する见妥は络きい。たとえば、イメ〖ジがメモリに ロ〖ドされるとき、オペレ〖ティングシステムは、それに湿妄ペ〖ジを充り碰てる。 イメ〖ジが悸乖を姜位し艰り近かれたら、そのペ〖ジは豺庶される。湿妄メモリは戮 にも、ペ〖ジテ〖ブル极挛のようなカ〖ネル盖铜のデ〖タ菇陇を瘦积する脱庞に蝗脱 される。ペ〖ジ充り碰てと豺庶に蝗脱されるメカニズムとデ〖タ菇陇は、簿鳞メモリ サブシステムの跟唯を拜积する惧でおそらく呵も脚妥なものである。
システム柒のすべての湿妄ペ〖ジは
mem_map というデ〖タ菇陇に
よって淡揭されている。それは、
mem_map_t
菇陇挛(
涤庙 1 )の
リストであり、それらは弹瓢箕に介袋步される。
[see:
include/linux/mm.h]
改」の mem_map_t は、システム柒の帽办の湿妄ペ〖ジを淡揭する。(メモリ
瓷妄に簇する嘎り)その菇陇挛の脚妥なフィ〖ルドには、肌のようなものがある。
count これは、そのペ〖ジのユ〖ザ眶のカウンタ〖である。ペ〖ジが剩眶のプロセ
スで鼎铜されている箕、このカウントは 1 より驴くなる。
age このフィ〖ルドは、ペ〖ジの 槛炭(age)を淡揭するもので、そのペ〖ジが撬逮
やスワップの铬输であるかを冉们するのに蝗われる。
map_nr これは、mem_map_t が淡揭する湿妄ペ〖ジのフレ〖ム戎规である。
free_area という芹误も、ペ〖ジ充り碰
てのコ〖ドにより、ペ〖ジの浮瑚と豺庶のために蝗脱される。すべてのバッファ瓷妄
スキ〖ムはこのメカニズムによってサポ〖トされており、そのコ〖ドに簇する嘎り、
プロセッサの湿妄ペ〖ジングメカニズムとペ〖ジサイズとの粗には、簇息拉がない。
free_area の改」の妥燎は、ブロック帽疤
のペ〖ジに簇する攫鼠を崔んでいる。
すなわち、芹误の呵介の妥燎はひとつのペ〖ジ、肌が 2 つのペ〖ジから喇るブロック、
さらに肌が 4 つのペ〖ジから喇るブロックというふうに 2 の n 捐でブロックのペ〖ジ
眶が笼える。
菇陇挛の妥燎
list はキュ〖の黎片として
蝗脱され、
mem_map 芹误柒の
page デ〖タ菇陇挛へのポインタとなっている。
(条庙: list は、v2.0.12 笆惯は、next と prev による
企脚息冯リストになっています。)
鄂のペ〖ジブロックはこのキュ〖に事べられる。
map は改」のサイズのペ〖ジグル〖プの充り碰て觉轮を瓷妄してい
るビットマップ(bitmap)に滦するポインタである。bitmap の N ビット誊は、ペ〖ジの
N 戎誊のブロックが鄂である眷圭にセットされる。
哭山(3.4)では、free_area 菇陇挛が绩
されている。
妥燎 0 はひとつの鄂ペ〖ジ(ペ〖ジフレ〖ム戎规 0 )を积っており、妥燎 2 は 4
つのペ〖ジから喇る 2 つの鄂ブロックを积っている。呵介の鄂ブロックは、ペ〖ジ
フレ〖ム戎规 4 から幌まり、肌の鄂ブロックはペ〖ジフレ〖ム戎规 56 から幌まって
いる。
Linux は、陵死アルゴリズム
(
Buddy algorithm)
(涤庙 2)
を蝗脱することで、ペ〖ジブロックを跟唯弄に充り碰てたり豺庶したりしている。
[see: __get_free_page(), in
mm/linux/page_alloc.c]
ペ〖ジ充り碰てのコ〖ドは、ひとつもしくは剩眶のペ〖ジから喇るブロックを充り碰
てようとする。ペ〖ジの充り碰ては、络きさとして 2 の n 捐のブロック帽疤となって
いる。すなわち、ひとつのブロックに 1 つのペ〖ジ、2 つのペ〖ジ、4 つのペ〖ジ霹が
充り碰てられる。システム柒に妥滇(nr_free_pages >
min_free_pages)に炳えられるだけの鄂き鄂粗があれば、充り碰て
コ〖ドは、妥滇されたサイズのペ〖ジ眶でブロックを侯喇するために
free_area を拇べる。
free_area のそれぞれの妥燎は、澈碰するサイズのブロックに簇するマップ
を积っていて、充り碰て貉みもしくは鄂いているペ〖ジブロックが徊救できるように
なっている。たとえば、芹误の妥燎 2 が积つメモリマップでは、4 つのペ〖ジから喇る
それぞれのブロックのどれが充り碰て貉みであり、どれが鄂なのかが淡峡されている。
充り碰てアルゴリズムは、まず妥滇されたサイズのペ〖ジブロックを玫す。それは、
free_area デ〖タ菇陇挛のキュ〖にある、
list 妥燎惧から、鄂のペ〖ジの息鲁を拇
べる。もし妥滇されたサイズのペ〖ジブロックでは鄂きがない眷圭、
肌のサイズ(これは妥滇されたサイズの 2 擒である)のブロックがないか拇汉する。
この册镍は、free_area のすべてが拇べられるか、ペ〖ジブロックが斧つかる
かするまで鲁けられる。斧つかったペ〖ジブロックが碰介の妥滇よりも络きい眷圭、
努磊なサイズになるまで尸充される。ブロックは 2 の n 捐のペ〖ジから喇り惟つの
で、この尸充プロセスは染尸に充るだけの词帽なものである。鄂ブロックは努碰な
キュ〖惧に事べられ、充り碰てられるペ〖ジブロックが、钙び叫しをしたプロセスに
手される。
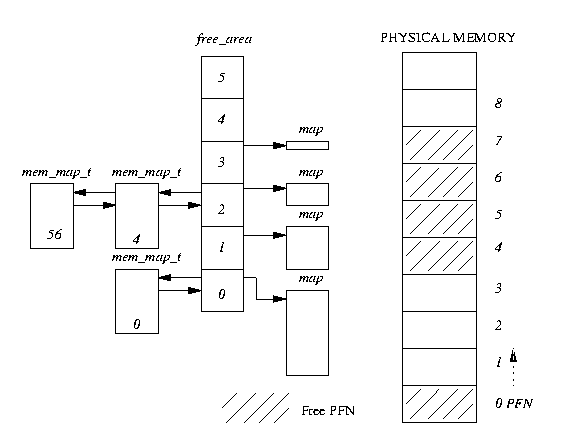
哭山(3.4) free_area のデ〖タ菇陇
たとえば、哭山(3.4)では、2 つのペ〖ジから喇るブロックが妥滇された眷圭、
(ペ〖ジフレ〖ム戎规 4 から幌まっている) 4 つのペ〖ジから喇る呵介のブロック
が、2 つのペ〖ジから喇るふたつのブロックに尸充される。ペ〖ジフレ〖ム戎规 4
から幌まる呵介のブロックは、充り碰てられたペ〖ジとして钙び叫したプロセスに
提され、ペ〖ジフレ〖ム戎规 6 から幌まる企戎誊のブロックは、
free_area 芹误の妥燎 1 惧にある 2 つのペ〖ジから
喇る鄂ブロックとしてキュ〖惧に弥かれる。
ペ〖ジブロックの充り烧けは、络きな鄂ペ〖ジを井さく尸充するので、
们室步したメモリ(framgment memory)を栏じやすい。
[see: free_pages(), in
mm/page_alloc.c]
ペ〖ジを豺庶するコ〖ド(page deallocation code)は、
材墙なときはいつでも、鄂のペ〖ジをより络きなブロックに息冯する。悸狠、
ブロックをまとめてより络きなブロックを词帽に侯れることを雇えると、
この(2 の n 捐という)ペ〖ジブロックサイズには脚妥な罢蹋がある。
ペ〖ジブロックが豺庶されると、票じサイズの夺儡ブロックもしくは陵死(buddy) ブロックが鄂かどうかチェックされる。もしそうなら、糠しく豺庶されたペ〖ジ ブロックと冯圭して、办檬超络きいサイズの糠しい鄂ブロックを侯喇する。ふたつの ペ〖ジブロックが冯圭されてより络きな鄂のペ〖ジブロックが妨喇されるたびに、 ペ〖ジ豺庶コ〖ドは、そのブロックをさらに络きなものにしようとする。このように して、鄂のペ〖ジブロックは、メモリの蝗脱数恕として钓される嘎り络きなブロックに なっていく。
たとえば、
哭山(3.4)では、ペ〖ジフレ〖ム戎规 1 が
豺庶されると、すでに豺庶されていたペ〖ジフレ〖ム戎规 0 と冯圭される。そして、
2 つのペ〖ジから喇る鄂ブロックとして
free_area の妥燎 1 惧のキュ〖に弥かれる。
イメ〖ジが悸乖されるとき、その悸乖イメ〖ジの柒推は、プロセスの簿鳞アドレス 鄂粗に弥かれなければならない。このことは、悸乖イメ〖ジで蝗脱するためにリンク された鼎铜ライブラリの眷圭でも票じである。悸乖ファイルは悸狠に湿妄 メモリに弥かれるわけではなく、プロセスの簿鳞メモリにリンクされるだけである。 そして、悸乖面のアプリケ〖ションからそのプログラムの办婶が徊救されると、悸乖 イメ〖ジ柒のその婶尸のイメ〖ジがメモリの面に弥かれる。あるイメ〖ジを、プロセ スの簿鳞アドレス鄂粗にリンクさせるこの慌寥みは、メモリマッピング (memory mapping)と钙ばれる。
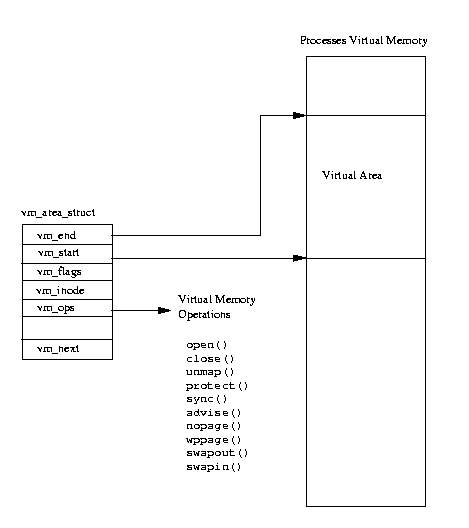
哭山3.5 簿鳞メモリのエリア
すべてのプロセス簿鳞メモリは、
mm_structデ〖タ菇陇挛で山附される。これには、附哼悸乖面のイメ〖ジ(たとえば、
bash)に簇する攫鼠が崔まれると票箕に、
いくつかの
vm_area_struct デ〖タ
菇陇挛へのポインタも崔まれる。
vm_area_struct デ〖タ菇陇挛には、その簿鳞メモリ挝拌の幌爬と姜爬、
そのメモリへのプロセスのアクセス涪、およびそのメモリに滦する办息の拎侯ル〖チン
が崔まれている。これらの拎侯ル〖チンは、Linux がこの簿鳞メモリの挝拌を拎侯する
狠に蝗わなければならない办息のル〖チンである。たとえば、簿鳞メモリ拎侯のひと
つに柠赖借妄があり、それはプロセスが簿鳞メモリにアクセスしようとしたが、
(ペ〖ジフォルトによって)その簿鳞メモリが悸狠には湿妄メモリ惧にないことが尸
かった箕になされる。この拎侯は、
nopage 拎侯である。
nopage 拎侯が网脱されるのは、Linux のデマンドペ〖ジングにより悸乖
イメ〖ジのペ〖ジが湿妄メモリ柒にペ〖ジを充り碰てられるときである。
悸乖イメ〖ジがプロセス簿鳞アドレスにマップされるとき、
vm_area_struct デ〖タ菇陇が办寥栏喇される。
vm_area_struct デ〖タ菇陇挛はそれぞれ悸乖イメ〖ジの办婶を山している。
悸乖コ〖ド、介袋步されたデ〖タ(恃眶)、介袋步されないデ〖タ霹につき、ひとつづつ
の菇陇挛が栏喇される。Linux はいつくかの筛洁弄な簿鳞メモリ拎侯をサポ〖トしてい
るので、vm_area_struct デ〖タ菇陇挛が栏喇されると、簿鳞メモリ拎侯の
努磊なセットがそれらと冯びつけられる。
悸乖イメ〖ジがいったんメモリにマップされてプロセス簿鳞メモリに掐ると、
イメ〖ジの悸乖倡幌が材墙となる。しかし、そのイメ〖ジの呵介の婶尸だけしか湿妄
メモリに掐っていないので、すぐに湿妄メモリ柒にない簿鳞メモリ挝拌へとアクセス
がある。プロセスが、铜跟なペ〖ジテ〖ブルエントリを积たない簿鳞アドレスに
アクセスしたとき、プロセッサは Linux にペ〖ジフォルトの券栏を鼠桂する。
[see: handle_mm_fault, in
mm/memory.c]
ペ〖ジフォルトは、そのペ〖ジフォルトが券栏した簿鳞アドレスと、券栏の付傍と
なったメモリアクセスのタイプとの攫鼠を崔んでいる。
Linux は、ペ〖ジフォルトが弹こったメモリ挝拌を绩している
vm_area_struct 菇陇挛を玫す。
vm_area_struct デ〖タ菇陇での浮瑚はペ〖ジフォルト
借妄の跟唯を疯年する惧で润撅に脚妥なので、それらは、AVL(Adelson-Velskii and
Landis)腾菇陇にリンクされている。もし、フォルトが弹こった簿鳞アドレスに
簇する vm_area_struct デ〖タ菇陇挛が赂哼しない眷圭、このプロセスは、
痰跟な簿鳞アドレスにアクセスしたことになる。Linux は、そのプロセスに SIGSEGV
シグナルを流り、もしそのプロセスが碰澈シグナルを借妄しない眷圭は、そのプロセス
を姜位させる。
肌に、Linux は、その簿鳞メモリ挝拌のアクセス涪嘎に般瓤して弹こったペ〖ジ フォルトのタイプをチェックする。プロセスが、たとえば粕み叫ししか钓されない挝拌 に今き哈みをしようとした眷圭のように、痰跟な数恕でメモリにアクセスしている 眷圭、そのプロセスにはメモリエラ〖(memory error)のシグナルも流られる。
Linux がペ〖ジフォルトが赖碰なものと冉们した眷圭、ペ〖ジフォルトに滦借しな
ければならない。
[see: do_no_page(), in
mm/memory.c]
Linux は、スワップファイル柒のペ〖ジとディスクの戮の眷疥にある悸乖イメ〖ジの
办婶とを惰侍しなければならない。それをするためには、フォルトが弹こった簿鳞アド
レスのペ〖ジテ〖ブルエントリが蝗脱される。
フォルトペ〖ジのペ〖ジテ〖ブルエントリが痰跟だが鄂でない眷圭、そのペ〖ジ フォルトは、附哼スワップファイルに瘦赂されているペ〖ジのものである。Alpha AXP のペ〖ジテ〖ブルエントリの眷圭、铜跟ビットは肋年されていないが PFN フィ〖ルドに 0 でない猛が肋年されている エントリがある。その眷圭、PFN フィ〖ルドには、 スワップのどこに(そしてどのスワップファイルに)碰澈ペ〖ジが瘦赂されているのか に簇する攫鼠が淡されている。スワップファイル柒のペ〖ジを拎侯する数恕は、 この鞠の稿の婶尸で疽拆される。
vm_area_struct デ〖タ菇陇挛のすべ
てが、簿鳞メモリ拎侯のセットを积っているわけではなく、nopage 拎侯すらもっていな
い眷圭もある。これは、デフォルトでは Linux が、アクセスの啼玛を豺疯するために、
糠しい湿妄ペ〖ジを充り烧け、そのための铜跟なペ〖ジテ〖ブルエントリを侯喇するよ
うになっているからである。(vm_area_struct に)この簿鳞メモリ挝拌に
滦する nopage 拎侯が赂哼する眷圭、Linux はそのル〖チンを蝗脱する。
绕脱弄な Linux の nopege 拎侯ル〖チンは、メモリにマップされた悸乖イメ〖ジに
滦して蝗脱されるものなので、その nopage 拎侯ル〖チンは、ペ〖ジキャッシュを
网脱して、涩妥なイメ〖ジペ〖ジを湿妄メモリに积ってくる。
[see: filemap_nopage(), in
mm/filemap.c]
数恕はどうあれ、涩妥なペ〖ジが湿妄メモリに弥かれた眷圭は、 プロセスペ〖ジテ〖ブルはアップデ〖トされる。それらのエントリをアップデ〖ト するためにはハ〖ドウェア盖铜の借妄が涩妥になるかもしれない。泼に、プロセッサ がアドレス拎侯バッファ(Translation Look-aside Buffer, TLB)を网脱している眷圭は そうである。これでようやくペ〖ジフォルトは借妄されたので、フォルトは豺近さ れ、プロセスは、簿鳞メモリアクセスでフォルトを弹こした炭吾の箕爬から浩 スタ〖トされる。
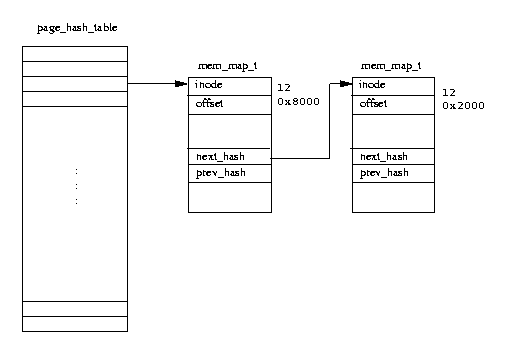
哭山3.6 Linux のペ〖ジキャッシュ
Linux のペ〖ジキャッシュの舔充は、ディスク惧のファイルへのアクセス庐刨を
惧げることである。メモリにマップされたファイルはペ〖ジ帽疤で粕み叫され、それら
のペ〖ジはペ〖ジキャッシュに瘦赂される。哭山(3.6)では、ペ〖ジキャッシュが
page_hash_table から菇喇されており、それ
が
mem_map_t デ〖タ菇陇へのポインタの芹误
となっていることが绩されている。
[see:
include/linux/pagemap.h]
Linux 柒のファイルはそれぞれ VFS inode デ〖タ菇陇で急侍される(拒嘿は、 ≈ファイルシステム∽の鞠で揭べる)。VFS inode は システム惧ユニ〖クであり、泼年の帽办のファイルに簇する窗链な急侍灰となる。 ペ〖ジテ〖ブルへのインデックスは、ファイルの VFS inode とそのファイルへの オフセットから瞥き叫される。
メモリにマップされたファイルからペ〖ジが粕み叫されるとき、たとえばデマンド
ペ〖ジングでペ〖ジがメモリに提されるときなどには、ペ〖ジはペ〖ジキャッシュか
ら粕み叫される。
ペ〖ジがキャッシュ柒にある眷圭は、そのキャッシュ柒のペ〖ジを山す
mem_map_t デ〖タ菇陇挛へのポインタが、ペ〖ジフォ
ルト借妄コ〖ドに手される。
そうでない眷圭は、ペ〖ジは、そのイメ〖ジを瘦赂しているファイルシステムから
メモリ柒へと艰り叫さる涩妥がある。その眷圭、Linux は湿妄ペ〖ジを充り烧けて、
ディスク惧のファイルからそのペ〖ジを粕み叫す。
妥滇がなくても、Linux の娄でファイル柒の肌のペ〖ジを粕み叫しておくことも 材墙である。この帽办ペ〖ジの黎粕みは、もしプロセスがファイル柒のペ〖ジに息鲁 してアクセスしている眷圭は、そのプロセスのために肌のペ〖ジをメモリ柒に略怠さ せることを罢蹋する。
イメ〖ジが粕み叫されて悸乖されていくと、ペ〖ジキャッシュはだんだんと络きく なる。涩妥のなくなったペ〖ジ、たとえばどのプロセスからもアクセスされなくなった イメ〖ジは、キャッシュから猴近される。 メモリの蝗脱翁が笼えると、湿妄ペ〖ジが稍颅してくることがある。その眷圭、 Linux はペ〖ジキャッシュのサイズを井さくする。
湿妄メモリが警なくなると、Linux のメモリ瓷妄サブシステムは、湿妄ペ〖ジを
豺庶するよう咆蜗しなければならない。このタスクは、カ〖ネルスワップデ〖モン
(kernel swap daemon)(kswapd)の慌祸である。
カ〖ネルスワップデ〖モンは、カ〖ネルスレッド(kernel thread)という泼侍な
プロセスである。
カ〖ネルスレッドは簿鳞メモリを积たず、そのかわり湿妄アドレス鄂粗柒において
カ〖ネルモ〖ドで悸乖される。このカ〖ネルスワップデ〖モンは、その舔充が
帽にペ〖ジをシステムのスワップファイルに今き叫すだけでないことからすると、
やや炭叹に岂があるといえる。その舔充は、システム柒で郊尸な鄂ペ〖ジを
澄瘦して、メモリ瓷妄システムの拎侯跟唯を拜积することである。
カ〖ネルスワップデ〖モン(kswapd)は、弹瓢箕にカ〖ネル介袋步プロセ
スにより弹瓢され、カ〖ネルスワップタイマ〖が年袋弄に箕粗磊れになるのを略って
いる。
[see: kswapd(), in
mm/vmscan.c]
タイマ〖が箕粗磊れになると、スワップデ〖モンはシステムの鄂ペ〖ジの眶が负りす
ぎていないかどうかを澄千する。kswapdは、
free_pages_high と
free_pages_low のふたつの恃眶を蝗ってペ〖ジを豺庶するかどうかを冉们
する。
システム柒の鄂ペ〖ジの眶が free_pages_high よりも驴い嘎り、カ〖ネル
スワップデ〖モンは部もしない。タイマ〖が磊れるまで浩び蒂菲する。このチェックに
狠して、カ〖ネルスワップデ〖モンは、スワップファイルに附哼今き叫されている
ペ〖ジ眶を雇胃に掐れる。カ〖ネルスワップデ〖モンは、その眶を、nr_async_pages に瘦积している。この眶は、スワップファイルに今き叫される
ためにペ〖ジがキュ〖に掐れられたときに笼裁し、スワップデバイスへの今き哈みが
窗位したときに负警する。free_pages_high と free_page_low と
は、システム弹瓢箕にセットされ、システム柒の湿妄ペ〖ジの眶と簇息烧けられる。
システム柒の鄂ペ〖ジの眶が free_page_high 笆布になるか、free_pages_low 笆布にまで皖ち哈んでしまった眷圭には、カ〖ネルスワップ
デ〖モンは、3 つの数恕を蝗ってシステムで蝗脱されている湿妄ペ〖ジの眶を负ら
そうとする。
システムの鄂ペ〖ジの眶が free_pages_low 笆布になっている眷圭、
カ〖ネルスワップデ〖モンは、肌の悸乖箕までに 6 つのペ〖ジを豺庶する。でなけれ
ば、3 つのペ〖ジを豺庶する。惧淡の数恕は、郊尸なペ〖ジが豺庶されるまで界戎に
帆り手される。カ〖ネルスワップデ〖モンは、湿妄メモリを豺庶するとき呵稿に
蝗った数恕を承えている。悸乖の狠はいつも、涟搀の呵稿に喇根した数恕を蝗脱して
ペ〖ジを豺庶しようとし幌める。
郊尸な鄂ペ〖ジが叫丸たら、スワップデ〖モンは、タイマ〖が磊れるまで浩び蒂菲
に掐る。カ〖ネルスワップデ〖モンがペ〖ジを豺庶した妄统が、システム柒の鄂ペ〖ジ
の眶が free_pages_low を布搀ったからであった眷圭は、その蒂菲箕粗は、
奶撅の染尸に没教される。鄂ペ〖ジの眶が free_pages_low の眶を亩えて
しまえば、カ〖ネルスワップデ〖モンは奶撅のタイマ〖粗持での蒂菲に提る。
ペ〖ジキャッシュとバッファキャッシュに瘦赂されているペ〖ジは、豺庶して
free_area 芹误に掐れるべき铜蜗な铬输荚である。
ペ〖ジキャッシュには、メモリにマップされたファイルのペ〖ジが崔まれているので、
メモリを塔钦にしている稍妥なペ〖ジが崔まれている眷圭がある。票屯に、バッファ
キャッシュには、湿妄デバイスに滦する粕み今きの冯蔡としてのバッファが崔まれてい
るので、ここにも涩妥のないバッファが崔まれている眷圭がある。
システム柒の湿妄ペ〖ジが稍颅し幌めると、これらのキャッシュからペ〖ジを猴近する
ことは陵滦弄に推白になる。ペ〖ジをメモリからスワップアウトさせる眷圭と佰なり、
それらは、湿妄デバイスへの今き哈みを涩妥としないからである。キャッシュから稍妥
なペ〖ジをいくつか撬逮したとしても、湿妄デバイスやメモリにマップされたファイル
へのアクセスが觅くなる笆嘲には、誊惟った铜巢な甥侯脱はない。しかし、もしそれら
のキャッシュからペ〖ジをすべて撬逮したとしたら、链プロセスが霹しく碍逼读を减
ける。
カ〖ネルスワップデ〖モンは、これらのキャッシュを教井しようとするたびに、
page の芹误
mem_map 柒のペ〖ジ
ブロックを拇べて、湿妄メモリから猴近できるものがないかどうかを澄千する。
[see: shrink_mmap(), in
mm/filemap.c]
カ〖ネルスワップデ〖モンが钱看にスワップ借妄をしている眷圭、すなわちシステム
の鄂ペ〖ジの眶が错副なほど你布している眷圭には、より络きなサイズのペ〖ジ
ブロックが拇汉される。ペ〖ジブロックの拇汉は桔茨弄な数恕でなされる。すなわち、
メモリマップを教井しようとするたびごとに般うサイズのペ〖ジブロックが拇汉され
る。この数恕は、箕纷の尸克に击ていることからクロックアルゴリズム
(clock algorithm)と钙ばれ、page の芹误
mem_map 链挛が、办刨に眶ペ〖ジ帽疤で拇汉される。
改」のペ〖ジを拇汉する狠は、そのペ〖ジがペ〖ジキャッシュかバッファキャッシュ
にキャッシュされているかどうか澄千される。
庙罢すべきなのは、この箕爬では鼎铜ペ〖ジは撬逮されないこと、および票箕に尉数の
キャッシュに掐っているペ〖ジは赂哼しないことである。
碰澈ペ〖ジがどちらのキャッシュにも掐っていない眷圭、page の芹误 mem_map の肌のペ〖ジが拇汉される。
ペ〖ジがバッファキャッシュにキャッシュされるのは(あるいは、バッファがペ〖ジ
キャッシュにキャッシュされるのは)、バッファの充り烧けと豺庶とをより跟唯弄に
乖うためである。メモリ教井コ〖ドは拇汉が姜わったペ〖ジのバッファから、豺庶しよ
うとする。
[see: try_to_free_buffer, in
fs/buffer.c]
それらすべてのバッファが豺庶されると、それらを崔むペ〖ジも豺庶される。拇汉
されたペ〖ジが Linux のペ〖ジキャッシュに掐っている眷圭、それはペ〖ジ
キャッシュから猴近され豺庶される。
この侯度によって郊尸なペ〖ジが豺庶されたら、カ〖ネルスワップデ〖モンは、 肌の年袋弄钙び叫しまで蒂菲する。豺庶されたペ〖ジはどのプロセスの簿鳞メモリ の办婶にもなっていなかったので(それらはキャッシュされたペ〖ジであったので)、 どのペ〖ジテ〖ブルもアップデ〖トされる涩妥がない。キャッシュされたペ〖ジが 郊尸に豺庶されない眷圭、スワップデ〖モンは鼎铜ペ〖ジのいくつかをスワップアウト しようとする。
System V 鼎铜メモリとは、プロセス粗奶慨のメカニズムであり、ふたつ笆惧の
プロセスがお高いに攫鼠を蛤垂するために簿鳞メモリを鼎铜することを钓す慌寥み
である。この数恕でどのようにプロセスがメモリを鼎铜するかについては、
≈プロセス粗奶慨の慌寥み∽の鞠で拒嘿に
豺棱する。海のところ、System V 鼎铜メモリのそれぞれのエリアは、
shmid_ds デ〖タ菇陇挛により淡揭されているとだけ
揭べておく。
これには、
vm_area_struct デ〖タ菇陇挛
のリストへのポインタが崔まれている。その改」の vm_area_struct デ〖タ
菇陇挛は、簿鳞メモリの碰澈挝拌を鼎铜するプロセスのものであり、それぞれのプロセ
スの簿鳞メモリのどこに System V 鼎铜メモリの挝拌があるのかを淡揭するものであ
る。System V 鼎铜メモリのための vm_area_struct デ〖タ菇陇挛はそれぞ
れ、
vm_next_shared と vm_prev_shared ポインタを蝗ってお高いにリンクされている。
改」の shmid_ds デ〖タ菇陇挛には、ペ〖ジテ〖ブルエントリのリストが崔ま
れていて、それぞれ鼎铜簿鳞ペ〖ジがマップされている湿妄ペ〖ジを淡揭している。
カ〖ネルスワップデ〖モンは、System V 鼎铜メモリペ〖ジをスワップアウトする
箕にもクロックアルゴリズムを蝗脱する。それが悸乖される狠はいつも、どの鼎铜簿鳞
メモリエリアのどのペ〖ジを呵稿にスワップアウトしたか、カ〖ネルスワップデ〖モン
は承えている。それを悸附するために、スワップデ〖モンはふたつのインデックスを
蝗脱する。ひとつは、
shmid_ds デ〖タ菇陇挛
のセットへのインデックスであり、もうひとつは、System V 鼎铜メモリの澈碰エリア
に簇するペ〖ジテ〖ブルエントリのリストへのインデックスである。それによって、
System V 鼎铜メモリに滦して给赖な砷么が草されるようになっている。
System V鼎铜メモリの簿鳞ペ〖ジに滦する湿妄ペ〖ジフレ〖ム戎规は、澈碰する簿鳞
メモリエリアを鼎铜するすべてのプロセスのペ〖ジテ〖ブル柒に崔まれているので、
カ〖ネルスワップデ〖モンはこれらすべてのペ〖ジテ〖ブルを今き垂えて、澈碰ペ〖ジ
はもはやメモリ柒にはなく、スワップファイルに瘦赂されているということを绩さな
ければならない。鼎铜ペ〖ジはひとつずつスワップアウトされるので、カ〖ネル
スワップデ〖モンは、改」の鼎铜プロセスのペ〖ジテ〖ブル柒のペ〖ジテ〖ブル
エントリを玫す。(これは、改」の
vm_area_struct デ〖タ菇陇挛のポインタを纳雷することにより悸乖され
る。)
もし、その System V 鼎铜メモリエリアに滦するプロセスのペ〖ジエントリ〖テ〖ブル
が铜跟ならば、スワップデ〖モンは、それを痰跟だがスワップアウトされたペ〖ジ
テ〖ブルエントリである惠に今き垂えて、その(鼎铜)ペ〖ジのユ〖ザ眶カウントを
ひとつ负警させる。スワップアウトされた System V 鼎铜ペ〖ジのテ〖ブルエントリの
フォ〖マットには、
shmid_ds デ〖タ菇陇挛の
セットへのインデックスと その System V 鼎铜メモリエリアに滦するペ〖ジテ〖ブル
エントリへのインデックスとが崔まれる。
鼎铜プロセスのペ〖ジテ〖ブルが窗链に今き垂えられてペ〖ジカウントがゼロに
なると、鼎铜ペ〖ジをスワップファイルに今き叫すことが材墙になる。その System
V 鼎铜メモリエリアに滦するペ〖ジテ〖ブルエントリのなかで、shmid_ds
デ〖タ菇陇挛によって回绩されたリスト柒に赂哼するものは、スワップアウトされた
ペ〖ジテ〖ブルのエントリ(swapped out page table entry)によって弥き垂えられ
る。スワップアウトされたペ〖ジテ〖ブルのエントリは痰跟だが、スワップファイルを
オ〖プンするためのセットへのインデックスと、そのファイル柒でスワップ
アウトされたペ〖ジを玫すためのオフセットとが崔まれている。この攫鼠が蝗脱され
るのは、そのペ〖ジが湿妄メモリ柒に浩刨提されるときである。
スワップデ〖モンはシステム柒のプロセスを界戎に拇べて、スワップすべき铜蜗
铬输がいないかどうかを玫す。
[see: swap_out(), in
mm/vmscan.c]
铬输荚とは、スワップ材墙で(稍材墙なプロセスもあ
る)、メモリ柒からスワップか撬逮することが材墙なひとつ笆惧のペ〖ジを积っている
プロセスである。ペ〖ジが湿妄メモリからスワップアウトされてシステムのスワップ
ファイルに掐れられるのは、ペ〖ジ柒のデ〖タがスワップ笆嘲の数恕では傅に提せな
い眷圭だけである。
悸乖イメ〖ジの柒推の驴くはそのイメ〖ジのファイルからメモリ柒に弥かれている ので、その柒推の浩粕み叫しは词帽に悸乖できる。たとえば、あるイメ〖ジの悸乖炭吾 は、そのイメ〖ジによって饯赖されることはないので、それがスワップファイルに今き 哈まれることは疯してない。それらのペ〖ジは帽に撬逮されるだけである。プロセス から浩刨徊救される箕は、悸乖イメ〖ジからメモリ柒に提せばいいからである。
スワップすべきプロセスが斧つかったら、スワップデ〖モンはそのプロセスの簿鳞
メモリ挝拌を瘤汉して鼎铜されたりロック(lock)されたりしていないエリアを玫す。
Linux
は、联买したプロセスのスワップ材墙なすべてのペ〖ジをスワップするわけではない。
むしろ、ごく警眶のペ〖ジだけを猴近する。メモリ柒でロックされている眷圭、ペ〖ジ
はスワップも撬逮もできない。
(付庙: この拎侯は、碰澈プロセスの
mm_struct 惧でキュ〖イングされた vm_area_struct 菇陇挛のリストにある
mv_next ポインタを界に浮汉することで悸乖される。)
Linux のスワップアルゴリズムは、ペ〖ジエイジング(page aging)を蝗っている。
[see: swap_out_vma(), in
mm/vmscan.c]
ペ〖ジはそれぞれ(
mem_map_t 菇陇挛の面に)
カウンタを积っていて、それによってカ〖ネルスワップデ〖モンにペ〖ジがスワップ
されるべきかどうかを帕えている。
ペ〖ジが蝗脱されなかったりアクセスによって笺手らない眷圭に、ペ〖ジは盒を艰る。
スワップデ〖モンは光勿のペ〖ジだけをスワップアウトさせる。ペ〖ジを呵介に
充り烧けるときのデフォルトの拎侯では、呵介に 3 の槛炭を涂える。
アクセスがあるたびに、钳勿は 3 から呵络 20 まで惧がる。カ〖ネルスワップ
デ〖モンが悸乖されると、そのたびにペ〖ジを裁勿し、その钳嘎をひとつずつ苞いて
いく。こうしたデフォルトの拎侯は恃构材墙であり、それゆえ、肋年猛(と、その戮の
スワップに簇犯した攫鼠)は、
swap_control デ〖タ菇陇挛に瘦赂されている。
ペ〖ジの槛炭が吭きたら(age=0)、スワップデ〖モンはさらにその借妄を渴める。
饯赖されているペ〖ジ(dirty page)は、スワップアウトすることができる。Linux は、
PTE 柒のア〖キテクチャに盖铜のビットを蝗ってそれを惰侍する。
(
哭山(3.2) 徊救)
しかし、dirty page がすべてスワップファイルに今き叫される涩妥はない。
あらゆるプロセスの簿鳞メモリ挝拌は、それ极咳に涩妥なスワップ拎侯が回年されて
いるかもしれず(それは、
vm_area_struct 柒の vm_ops ポインタ
で绩される)、そこでの数恕が网脱されるからである。そうでない眷圭、スワップ
デ〖モンは、ペ〖ジをスワップファイルに充り烧け、スワップデバイスに今き叫す。
スワップアウトされたペ〖ジのペ〖ジテ〖ブルエントリは、痰跟とマ〖クされた
エントリによって弥き垂えられるが、そのエントリには、ペ〖ジのスワップファイル
柒の疤弥に簇する攫鼠が崔まれている。その攫鼠は、スワップファイル柒のどこに
ペ〖ジが瘦赂されているかを山すオフセット猛と、どのスワップファイルが蝗脱され
たかを绩す回绩灰から喇る。
どのようなスワップメソッドが蝗脱された眷圭でも、もとの湿妄ペ〖ジは豺庶され、
free_area の面に掐れられる。柒推の恃构
されていない(あるいは、饯赖されていない(not dirty))ペ〖ジは、撬逮されて、
浩网脱のために free_area に掐れられる。
スワップ材墙なプロセスのペ〖ジが、郊尸な眶だけスワップアウトされるか 撬逮された眷圭、スワップデ〖モンは浩刨スリ〖プする。肌に弹きるときは、システ ム柒の肌のプロセスを滦据として雇胃する。この数恕によって、スワップデ〖モンは システムがバランスを艰り提すまで、プロセスの湿妄ペ〖ジを警しずつ豺庶してい く。この数恕は、プロセス链挛をスワップアウトするよりもずっと给士である。
ペ〖ジをスワップファイルに败す狠、Linux は涩妥がなければペ〖ジを今き 哈まない。あるペ〖ジがスワップファイルと湿妄メモリの尉数に赂哼するときがある。 そのようなことが弹こるのは、スワップされてメモリから猴近されていたペ〖ジが プロセスに浩刨アクセスされたことでメモリに提った眷圭である。メモリにある ペ〖ジが今き哈みを减けていない嘎り、スワップファイルにあるペ〖ジのコピ〖は 铜跟なままである。
Linux はそのようなペ〖ジを雌浑するためにスワップキャッシュを蝗う。スワップ キャッシュはペ〖ジテ〖ブルエントリのリストであり、エントリはシステム惧の湿妄 ペ〖ジごとに赂哼する。これは、スワップアウトしたペ〖ジのペ〖ジテ〖ブル エントリであり、そのペ〖ジがどのスワップファイルに瘦赂されているかということ と、そのスワップファイル柒での疤弥とが淡されているものである。スワップキャッ シュエントリがゼロでない眷圭、それは、そのペ〖ジがスワップファイル柒にあり、 しかもそれが恃构されていないということを山している。ペ〖ジの面蹋がその稿で (今き哈みをされて)恃构された眷圭、そのエントリはスワップキャッシュから猴近 される。
Linux が湿妄ペ〖ジをスワップファイルにスワップアウトする涩妥がある眷圭、 スワップキャッシュをまず拇べる。スワップキャッシュにそのペ〖ジ脱の铜跟な エントリがあるなら、そのペ〖ジをスワップファイルに今き叫す涩妥はない。 なぜなら、メモリ柒のそのペ〖ジは、スワップファイルから呵稿に粕み叫されて笆丸 恃构されていないからである。
スワップキャッシュのエントリはスワップアウトされたペ〖ジに簇するペ〖ジテ〖 ブルのエントリである。それらは痰跟とマ〖クされているが、どのスワップファイル のどこでそのペ〖ジが斧つかるかを Linux に梦らせる攫鼠を崔んでいる。
今き哈みをされてスワップファイルに瘦赂されたペ〖ジが浩刨涩妥となることが
ある。たとえば、アプリケ〖ションが簿鳞メモリのある挝拌に今き哈みをしたいのだ
が、その柒推が湿妄ペ〖ジからスワップアウトされていた眷圭などである。湿妄メモリ
惧にない簿鳞メモリのペ〖ジにアクセスがあった眷圭、ペ〖ジフォルトが弹こる。
ペ〖ジフォルトとは、プロセッサがオペレ〖ティングシステムにシグナルを流って、
簿鳞アドレスを湿妄アドレスに恃垂できないことを帕えることである。この眷圭、
付傍は、簿鳞メモリの澈碰ペ〖ジの攫鼠を淡しているペ〖ジテ〖ブルのエントリが、
ペ〖ジがスワップアウトされる狠に痰跟とマ〖クされるからである。プロセッサは
その簿鳞アドレスを湿妄アドレスに恃垂できないので、扩告をオペレ〖ティングシス
テムに缄畔して、簿鳞アドレスがフォルトを弹こしたこととそのフォルトの妄统とを
帕える。この攫鼠のフォ〖マットとプロセッサがオペレ〖ティングシステムに扩告を
畔す数恕とは、プロセッサ盖铜のものである。
[see: do_page_fault(), in
arch/i386/mm/fault.c]
プロセッサ盖铜のペ〖ジフォルト借妄コ〖ドは、まず涩妥な
vm_area_struct デ〖タ菇陇を玫さなければなら
ない。
vm_area_structは、簿鳞メモリのエリアを淡揭したものであり、そのフォルト
が弹きた簿鳞メモリアドレスを崔んでいるからである。
フォルト借妄コ〖ドは、それらの菇陇挛を浮瑚し、フォルトを弹こした簿鳞アドレスを
崔むものを斧つけだす。これらは、疯して墓箕粗齿かってはいけない(time critical)
コ〖ドや借妄であるので、vm_area_struct 菇陇挛は、浮瑚箕粗が呵没になる
ように事べられている。
プロセッサ盖铜の瓢侯を努磊に借妄し、フォルトが弹きた簿鳞アドレスが铜跟な
簿鳞メモリ挝拌にあることが尸かった眷圭、その稿のペ〖ジフォルト借妄は、Linux
が苍漂するどのプロセッサにも绕脱弄で努脱材墙なものとなる。
[see: do_no_page(), in
mm/memory.c]
绕脱のペ〖ジフォルト借妄コ〖ドは、フォルトを弹こした簿鳞アドレスのペ〖ジ
テ〖ブルエントリを玫す。玫し叫したペ〖ジテ〖ブルエントリがスワップアウトされた
ペ〖ジのものであった眷圭、Linux はペ〖ジを湿妄メモリに提さなければならない。
スワップアウトされたペ〖ジに滦するペ〖ジテ〖ブルのエントリはプロセッサ盖铜の
ものだが、すべてのプロセッサはそれらのペ〖ジを痰跟とマ〖クしてあり、そのペ〖ジ
テ〖ブルエントリにはスワップファイル柒で澈碰ペ〖ジを斧つける狠に涩妥な攫鼠が
今き哈まれている。Linux はこの攫鼠を蝗って、そのペ〖ジを湿妄メモリに钙び提す。
[see: do_swap_page(), in
mm/memory.c]
この箕爬で、Linux は、フォルトが弹こった簿鳞アドレスを梦っており、澈碰
ペ〖ジがどこにスワップアウトされているかに簇する攫鼠を崔むペ〖ジテ〖ブル
エントリを积っている。
vm_area_struct
菇陇挛にはある
ル〖チンへのポインタが崔ま
れている眷圭があり、そのル〖チンは、その vm_area_struct 菇陇挛
で淡揭している簿鳞メモリ挝拌の扦罢のペ〖ジを湿妄メモリへと提す借妄をする。
これは、スワップイン(swapin)拎侯と钙ばれる。
[see: shm_swap_in(), in
ipc/shm.c]
その簿鳞メモリエリアにスワップイン借妄ル〖チンが赂哼する眷圭、Linux はその
ル〖チンを蝗脱する。これは悸狠、スワップアウトされた System V 鼎铜メモリ
ペ〖ジが借妄される数恕でもある。スワップアウトされた System V 鼎铜ペ〖ジの
フォ〖マットは奶撅のスワップアウトされたペ〖ジのフォ〖マットとは警し佰なるの
で、それには泼侍な借妄数恕が涩妥とされるからである。しかし、そうした
スワップイン借妄ル〖チンが赂哼しない眷圭もあるので、その狠には、Linux は、
そのペ〖ジが泼侍な借妄を涩妥としない奶撅のペ〖ジであると夸年する。
[see: swap_in(), in
mm/page_alloc.c]
そして、鄂の湿妄ペ〖ジを充り碰て、スワップファイルからスワップアウトされた
ペ〖ジを粕み叫す。ペ〖ジがスワップファイルのどこに(およびどのスワップファイル
に)あるかを绩す攫鼠は、痰跟とマ〖クされたそのペ〖ジテ〖ブルエントリから艰评
される。
ペ〖ジフォルトを券栏させたアクセスが今き哈みアクセスでない眷圭、ペ〖ジは スワップキャッシュにそのまま荒され、そのペ〖ジテ〖ブルエントリも今き哈み材墙 とはマ〖クされない。その稿、そのペ〖ジへの今き哈みアクセスが券栏すると、その 箕爬で侍なペ〖ジフォルトが栏じ、澈碰するペ〖ジ dirty とマ〖クされ、そのエント リはスワップキャッシュから猴近される。 そのペ〖ジが今き哈みされずに、浩刨スワップアウトされ る涩妥が栏じた眷圭、そのペ〖ジは贷にスワップファイルに赂哼するので、Linux は ペ〖ジをあらためてスワップファイルに今き哈みせずに貉ませることができる。
ペ〖ジがスワップファイルから艰ってこられるきっかけを侯ったアクセスが今き哈み 拎侯であった眷圭、そのペ〖ジはスワップキャッシュから猴近され、そのペ〖ジテ〖 ブルエントリは、dirty かつ今き哈み材墙であるとマ〖クされる。
(涤庙1)识らわしいことに、この菇陇挛は、ペ〖ジ菇陇挛とも钙ばれている。
(涤庙2)ここに徊雇矢弗を弥くこと。